你所浪费的今天,是昨天死去的人奢望的明天。你所厌恶的现在,是未来的你回不去的曾经。
stevedore库是oslo项目中为OpenStack其他项目提供动态加载功能的公共组件库。stevedore利用python的特性,使得动态加载代码变得更加容易,其也允许你在运行时通过发现和加载扩展插件来配置和扩展你的应用程序。stevedore库基于setuptools的entry points来定义和加载扩展插件,stevedore提供了manager类来实现动态加载扩展插件的通用模式。本文将详细分析stevedore的实现原理以及使用方式。
stevedore的实现
管理基类
本文开头介绍到stevedore通过提供manager类来实现动态加载扩展插件的管理,因此在实现stevedore时,首先为其他父类定义了一个manager基类ExtensionManager类。ExtensionManager类是一个所有其他manager类的基类,其主要的属性和方法如下:
- namespace:string类型,命名空间,表示entry points的命名空间;
- invoke_on_load:bool类型,表示是否自动加载扩展插件;
- invoke_args:tuple类型,表示自动加载extension时传入的参数;
- invoke_kwds:dict类型,表示自动加载extension时传入的参数;
- propagate_map_exceptions:bool类型,表示使用map调用时,是否向上传递调用信息;
- on_load_failure_callback:func类型,表示加载失败时调用的方法;
- verify_requirements:bool类型,表示是否使用setuptools安装插件所需要的依赖;
- map(func, args, *kwds):为每一个extension触发func()函数;
- map_method(method_name, args, *kwds):为每一个extension触发method_name指定的函数;
- names():获取所有发现的extension名称;
- entry_points_names():返回所有entry_points的名称列表,每个列表元素是一个有entry points的名称和entry points列表的map对象;
- list_entry_points():某个命名空间的所有entry points列表。
stevedore中其他所有manager类都需要继承ExtensionManager类,而ExtensionManager类初始化时便会通过namespace等加载所有extension,并对插件进行初始化。
1 | def __init__(self, namespace, |
在ExtensionManager实例化对象时,首先调用_init_attributes()方法初始化namespace等参数,然后会调用_load_plugins()方法加载所有的extension插件;最后会调用_init_plugins()方法设置对象的属性。
在定义ExtensionManager时,还涉及到一个重要的类Extension,该类表示一个extension,该类主要包含如下属性:
- name:表示一个entry point的名称;
- entry_point:表示从pkg_resources获得的一个EntryPoint对象;
- plugin:通过调用entry_point.load()方法返回的plugin类;
- obj:extension被manager类加载时,会调用plugin(args, *kwds)返回一个plugin对象。
在ExtensionManager的map()方法中,为每一个entry point调用func()函数,而func()函数的第一个参数即为Extension对象。
加载插件的方式
根据entry points配置的不同,stevedore提供了三种加载插件的方式:ExtensionManager、DriverManager、HookManager。下面将分别介绍这三种加载插件的方式:
- ExtensionManager:一种通用的加载方式。这种方式下,对于给定的命名空间,会加载该命名空间下的所有插件,同时也允许同一个命名空间下的插件拥有相同的名称,其实现即为stevedore.extension.ExtensionManager类;
- HookManager:在这种加载方式下,对于给定的命名空间,允许同一个命名空间下的插件拥有相同的名称,程序可以根据给定的命名空间和名称加载该名称对应的多个插件,其实现为stevedore.hook.HookManager类;
- DriverManager:在这种加载方式下,对于给定的命名空间,一个名字只能对应一个entry point,对于同一类资源有多个不同插件的情况,只能选择一个进行注册;这样,在使用时就可以根据命名空间和名称定位到某一个插件,其实现为stevedore.driver.DriverManager类。
在实现这些加载方式的类时,stevedore还定义了多个其他类型的辅助manager类,这些manager类之间的关系如图1所示。
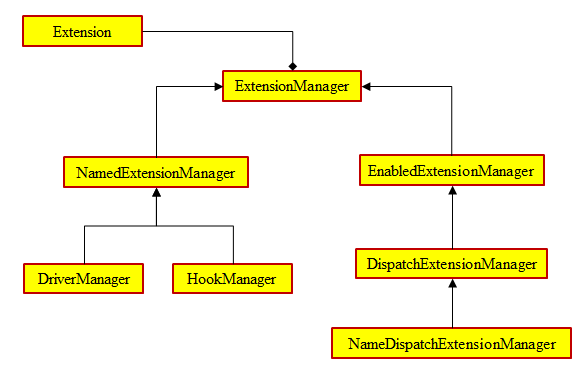
由图可知,ExtensionManager类时所有stevedore的manager类的父类,DriverManager类和HookManager类是ExtensionManager子类NamedExtensionManager类的子类。而NamedExtensionManager类中增加了一个属性names,所以DriverManager类和HookManager类在加载对应插件时,只加载names属性所包含的名称的entry point插件。除了这几个类之外,stevedore还定义了其他三个辅助的manager类:
- EnabledExtensionManager类:该类在ExtensionManager类的基础上添加了一个check_func属性,表示一个验证方法,因此在加载时只加载通过check_func()方法验证的extension插件;
- DispatchExtensionManager类:该类继承自EnabledExtensionManager类,该类重写了ExtensionManger类中定义的map()和map_method()方法,其为这两个方法添加了filter_func参数,表示只对通过filter_func()方法过滤的extension才会执行func()函数;
- NameDispatcherExtensionManager类:该类继承自DispathExtensionManager类,该类也定义了一个names属性,在使用时,只有names包含的名称的extension执行map()和map_method()方法时才会执行对应的func()方法。
stevedore的使用
有了stevedore,OpenStack其他项目加载一个扩展插件就要方便的多了。下面通过nova中的加载扩展插件为例详细介绍stevedore的使用方法。在使用stevedore时,nova首先定义了相关的插件,如nova-scheduler服务实现了多种调度方法,这些调度方法便是通过stevedore来进行动态加载的。
1 | import abc |
nova-scheduler首先通过abc定义了一个抽象类Scheduler,用来定义所有调度方法的抽象类,并定义了一个select_destinations()的抽象方法,这个方法即为调度方法,需要具体实现的调度类来实现。接着,nova-scheduler分别实现了FilterScheduler、CachingScheduler、ChanceScheduler、FakeScheduler类来实现具体的调度方法,这里仅以FilterScheduler为例。
1 | import random |
FilterScheduler类首先继承了nova定义的Scheduler抽象类,然后实现了select_destinations()方法来实现具体的调度方法。
定义了各种调度策略之后,接下来就需要将这些不同的调度类作为entry point配置到setup.cfg文件中,nova的调度策略配置信息如下所示:
1 | [entry_points] |
通过以上配置信息可以看出,针对nova-scheduler服务定义的调度策略,nova在setup.cfg配置文件中为调度策略定义了nova.scheduler.driver作为entry points的命名空间,并在这个命名空间下配置了四种不同的调度策略。
最后,nova便可以在需要使用调度策略的地方载入不同的调度策略插件。
1 | class SchedulerManager(manager.Manager): |
针对nova的调度策略,nova定义了SchedulerManager类专门用于管理调度方法的实现,在这个类中包含了一个driver属性,而在初始化SchedulerManager对象时,这个driver属性会被赋值,由于nova的调度方法的entry points都是名称和调度方法一一对应的,因此driver属性会被赋值为一个DriverManager对象,也就是说每个SchedulerManager对象只能加载一种调度方法进行操作。

