生活的模样很残酷,再苦再累,你都不能放弃,因为无路可退,进一步或许你会看到一方的壮阔苍旻;退一步或许你会万劫不复。你无法选择出生,但你可以选择奋发向上,用自己的辛劳和汗水去创造属于自己的人生,努力让自己过上自己想要过得生活。
Gnocchi 介绍
简介
之前我们已经介绍过了paste、WSGI、pecan等内容,每一个知识点,我们都详细分析了使用方式,pecan还分析了源码,下面我们就结合之前的几个知识点来分析一个项目的启动过程,以 openstack 项目 gnocchi 为例。
Gnocchi是一个能够高效存储海量监控指标(metric)测量值的系统,其设计目标是能够在云环境中提供时序数据库服务(TDBaaS,Time-series Database as a Service),通过对外暴露HTTPREST API来创建和操作各种监控资源的属性和各项监控指标的测量数据,最终实现了监控指标测量值的查询与存储的数据规模无关。Gnocchi最初由Julien Danjou于2014年发起,旨在为Ceilometer项目解决其最初利用传统关系型数据库作为监控数据存储后端时,遇到的扩展性问题,提供存储海量监控数据的服务。
架构
Gnocchi的架构实际上并不复杂,主要由三个服务组成:一个HTTP REST API服务(gnocchi-api),一个异步处理监控数据的守护程序(gnocchi-metricd)和一个可选的statsd兼容的守护程序(gnocchi-statsd)负责监听通过TCP或者UDP发送的计量数据。监控数据由HTTP REST API服务和statsd守护程序负责获取,而metricd守护程序则在后台负责对获取的数据进行各种操作,包括测量值的计算和聚合,过期监控指标的清除等。其中,API服务和metricd守护程序都是无状态的,可以轻松的根据负载情况进行扩展。
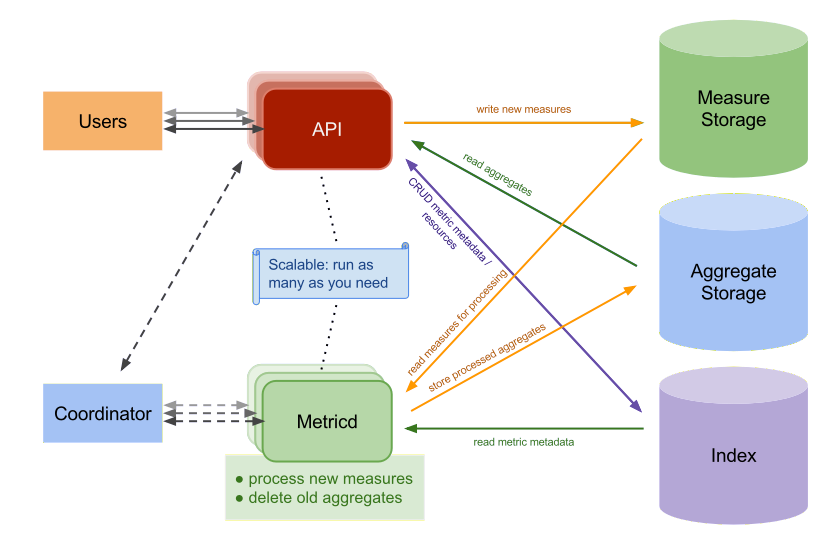
从图可以看出Gnocchi的服务主要包含两大服务,API和Metricd服务。同时可以看到有三个存储,Measure Storage、Aggregate Storage和Index。
Measure Storage:是经过ceilometer-agent-notification服务处理后发送过来的数据,是实际的监控数据,但这些数据还需要经过gnocchi服务处理,处理后就会删除掉。比如这部分数据就可以保存到file中,当然也支持保存到ceph,但这属于临时数据,所以用file保存就可以了。
Aggregate Storage:Aggreate是总数、合计的意思,gnocchi服务采用的是一种独特的时间序列存储方法,这个存储存放的是按照预定义的策略进行聚合计算后的数据,这样在获取监控数据展示时速度就会很快,因为已经计算过了。用户看到的是这层数据。后端存储包括file、swift、ceph,influxdb,默认使用file。可以保存到ceph中,这样可在任意一个节点上获取,但由于存储的都是大量小文件,大量的小文件对ceph来说并不友好。
Index:通常是一个关系型数据库(比如MYSQL),是监控数据的元数据,用以索引取出resources和metrics,使得可以快速的从Measure Storage和Aggregate Storage中取出所需要的数据。目前支持4种drivers,PostgreSQL(首选),MySQL(至少版本是5.6.4),
这些drivers提供了大多数相同的性能和特性,PostgreSQL具有更高的性能并且有一些额外的特性(例如 资源持续时长计算)。
API:gnocchi-api服务进程,可以托管到httpd服务一起启动,通过Indexer和Storage的driver,提供查询和操作ArchivePolicy,Resource,Metric,Measure的接口,并将新到来的Measure(也就是ceilometer-agent-notification发送到gnocchi-api服务的数据)存入Measure Storage。
Metricd:gnocchi-metricd服务进程,根据Metric定义的ArchivePolicy规则周期性的从Measure Storage中获取未处理的Measure数据并进行处理,将处理结果保存到Aggregate Storage中,同时也对Aggregate Storage中的数据进行聚合计算和清理过期的数据。
1 | gnocchi-metricd daemon会测量所有你的CPU功效来最大化CPU使用,当计算metric聚集。你可以使用gnocchi status命令查询HTTP API 获取监控项处理的聚集状态,它将会显示多少个监控项metric正在处理,正如处理存储的gnocchi-metricd。只要积压未办的时请不是持续增长,这意味着gnocchi-metricd能够处理正在被发送的个数的监控项。假如正在处理的measure的数量持续上升,你需要增加gnocchi-metricd daemons。你可以在任意数量的服务器上运行任意数量的metricd-daemon。 |
API和Metricd服务都是设计成了无状态的服务,可以横向拓展来加快数据的处理。
存储
gnocchi 目前支持不同的存储后端:
File(默认),Ceph(首选),OpenStack Swift,S3,Redis
这些后端是基于名叫Carbonara的中间件,该中间件是用来处理时间序列的操作,因为上述存储技术无法处理时间序列。Carbonara对于后面上述的支持是比较好的,并且是易于扩展的。Ceph和Sift原本就是比文件driver更具有扩展性的。根据你系统的大小,使用file driver并且存储你在磁盘上的数据一般各哦吟咏了。如果你需要扩展为数台服务器,你可以通过NFS来贡献数据。S3,Ceph和Swift drivers更容易扩展。Ceph提供了更好的一致性,因此推荐用Ceph。
可以在安装时进行指定:
1 | pip install gnocchi |
其中如果用ceph作为 back-end的话,需要满足以下要求:
1 | ceph需要一个已经创建的Ceph 用户和一个pool。它们可以被以下的例子来创建 |
指标
Gnocchi中有三层数据,resources -> metric -> measure
Resource:是gnocchi对openstack监控数据的一个大体的划分,比如虚拟机的磁盘的所有监控资源作为一个resource,可用命令gnocchi resource list查看
Metric:是gnocchi对openstack监控数据的第二层划分,归属于resource,代表一个较具体的资源,比如cpu值,可用命令gnocchi metric list查看
Measure:是gnocchi对openstack监控数据的第三层划分,归属于metric,表示在某个时间戳对应资源的值,可用命令gnocchi measures show metric_id
在Gnocchi中,一个时间序列是点的集合,在时间序列中的每一个点都有measure或者采样值sample。存储格式会被各种技术压缩,因此计算时间序列的大小在最坏情况下被下面的公式计算:
1 | 点的个数 * 8byte = 时间序列大小 |
时间序列处理:
1 | metric的measures到Gnocchi,这些值会被动态聚集。着意味着Gnocchi并不存储所有发送的measures,而是在一个时间段聚集它们。 |
示例
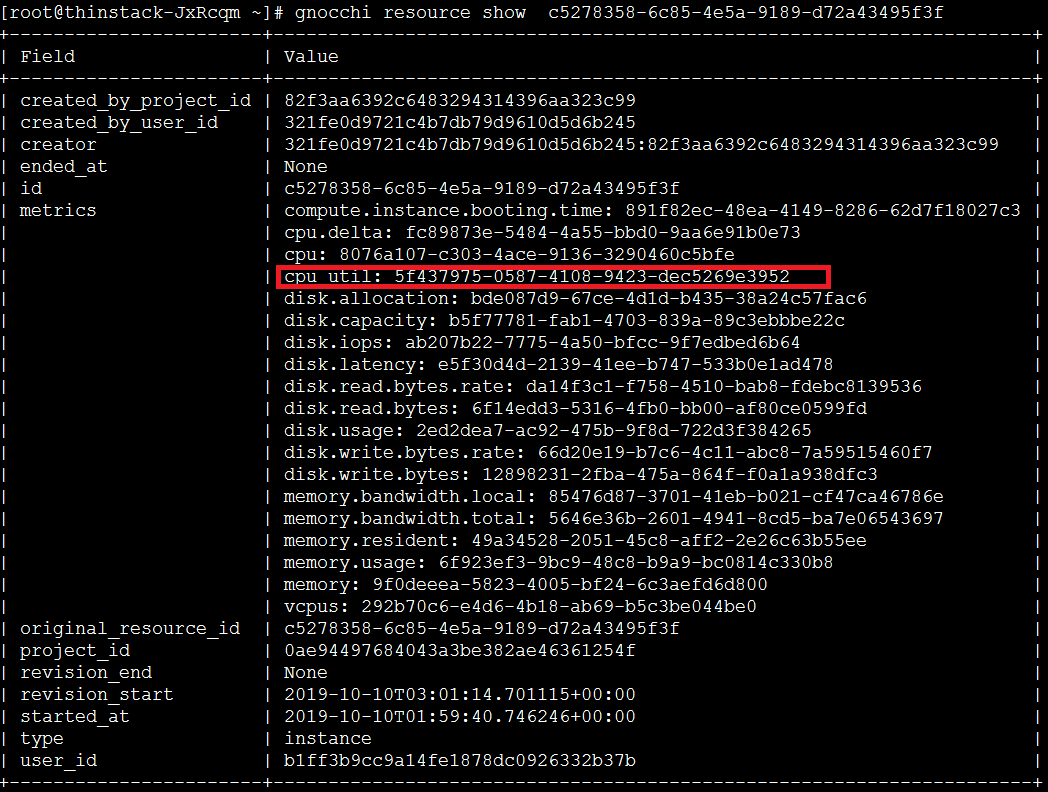
通过resource找metric
gnocchi resource show resource-id
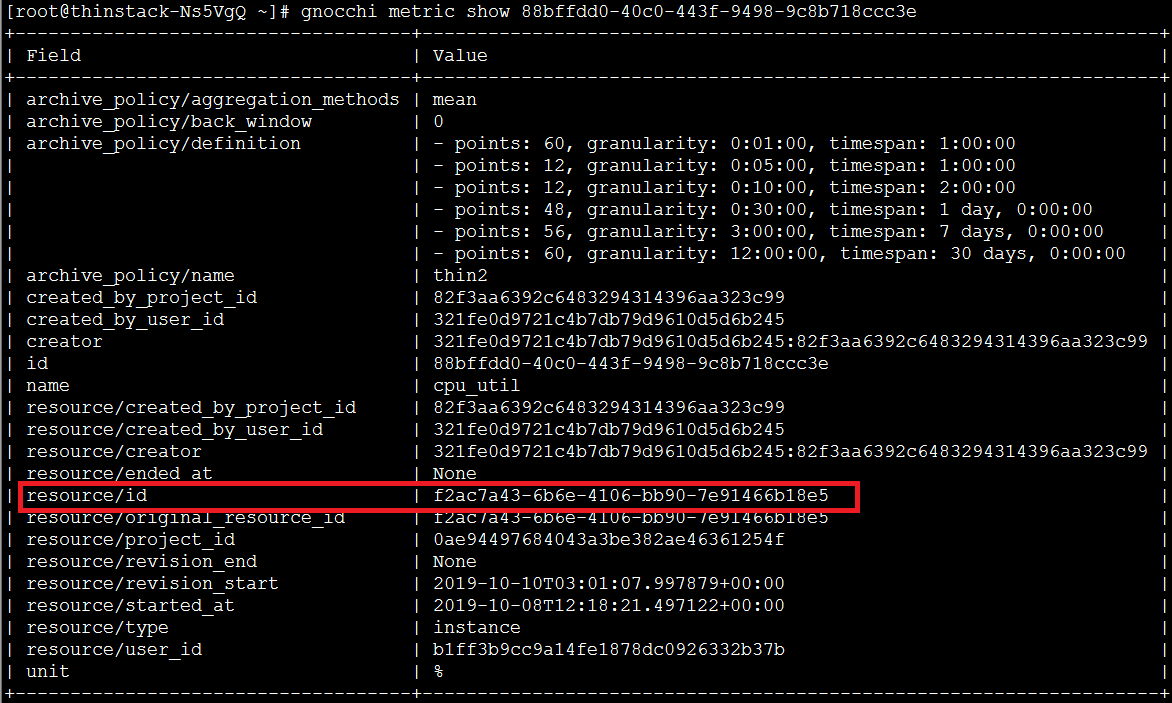
查看 metric 属性
gnocchi metric show metric-id
通过 metric 找 measures
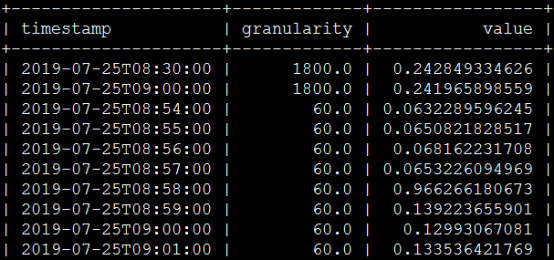
中间那个granularity值表示采集时间间隔,60表示60秒,1800表示30分钟,这个取决于我们自己设定的聚合计算策略,我这边设的策略如下:

归档
归档策略表示最后数据存储到后端时是什么形态,间隔多少,保存多久
2
3
4
5
6
7
8
>
> points:60,granularity:0:01:00表示只保存60个点,每个点间隔是1分钟,也就是只保存最新1小时的数据
>
> points:48,granularity:0:30:00表示只保存48个点,每个点间隔是30分钟,也就是只保存最新一天的数据
>
> 一些resource type和要计算的metric都定义在/etc/ceilometer/gnocchi_resources.yaml该文件中
>
Gnocchi中,归档策略定义是被表示为点的数量。如果你的归档策略定义了一个10各点的策略,粒度是1秒,时间序列归档将会维持10秒(有时会多一点),每一种表示是对超过1秒的聚集。这意味着时间序列将会最大保留最新到最老10秒的数据。但这并不意味着这是连续的10秒:可能数据中存在不规则的部分。
因此,归档策略和粒度完全依赖于你的使用情况。你可以定义其中归档策略。一个典型的低度使用的方式
3600 点,粒度1s ,等于1小时
1440点,1分钟,24小时
720点,一小时,30天
365点,一天,一年
这将表示每个聚集方法将花费6125个点 9 = 54 KB空间。如果你使用
8个标准的聚集方法,你的监控项占据的总空间为8 54KB = 432KB
小心定义你的归档策略,它将花费更多的CPU。因此,创建一个归档策略包含两个定义(
每天1秒的粒度粒度和针对每个月1分钟的粒度)将会花费两被的CPU比一个定义(例如:每天1秒的粒度)
默认归档策略
默认3个归档策略会在调用 gnocchi-upgrade 的时候被创建:
low , medium , high
描述了存储空间和CPU使用的需求。它们使用
default_arrgegation_methods
这是默认被设置为 mean , min, max , sum , std, count
一个fourth archive policy叫做bool的也默认被提供了。这仅仅用于存储boolean 值(例如,0和1).它仅仅为每一秒存储1个data point(使用 最后的聚集方法),是一年的保留时间。
最好的存储大小是被如下假设:除了0和1作为测量值measures被发送。如果其他的值被发送,最坏情况下的最大存储大小会被考虑在内。
1 | Low: |
Gnocchi 源码
之前我们分析过了 wsgi 、 pecan 和 paste 的相关知识,今天梳理一下 Gnocchi 的代码,顺便温习一下。
基于O版
api-server
在源码结构中 rest 目录是api转化为gnocchi可以处理请求的入口类,包含了许多Controller方法。由于gnocchi采用pecan(对象路由web框架来获取资源),这个文件提供的方法就是解析传递过来的url,通过对应方法解析后执行相关命令。
__init__.py :比较重要的方法包括:
- MetricController(继承自rest.RestController,提供post_measures添加测量值数组,获取某个监控项测量值列表方法get_measures);
- MetricsController(根据监控项id解析得到监控项交给MetricController处理);
- NamedMetricController(可根据监控项名称查询到监控项,根据资源id,类型,监控项列表来更新资源);
- MetricsMeasuresBatchController(重要,监控项测量值批处理控制器,实际上就是遍历每个监控项,将每隔监控项的采样值列表添加到数据库中)。
app.py :app.py是pecan应用的入口,包含应用初始化代码。
- hooks对应的配置是一些Pecan的hook,作用类似于WSGIMiddlewareGnocchiHook类(提供在Pecan尝试将一个请求分发给控制器的之前被调用)的函数on_route)
- load_app方法(Paste.Deploy主要是用来载入WSGI中的WebApp使用,其核心函数是loadapp()通过loadapp函数和一个配置文件或者egg包来载入WSGI应用,一个配置文件后缀为ini,内容被分为很多段):实际上是获取storage,indexer数据库驱动器,然后部署生成app并返回。
- build_server(): 执行: service.prepare_service(),执行: serving.run_simple
app.wsgi :主要调用conf = service.prepare_service(),application = app.load_app(conf)
我在部署 gnocchi-api 的时候使用的是 apache + mod_wsgi ,这种都是需要指定 wsgi 文件的位置,比如,我们可以如下配置:
1 | <VirtualHost *:8041> |
可以看到第四行指定了wsgi启动的路径,我们看下这个目录:
1 | from gnocchi.rest import app |
1 | def build_wsgi_app(): |
1 | def load_app(conf, indexer=None, storage=None, |
这里启动时,调用了 pasteDeploy 的 loadapp(一个简单的函数)就可以部署WSGI,而且不需要知道WSGI应用的细节。PasteDeploy的工作模式是使用一个配置文件configure.ini去解析URL。gnocchi的配置是api-paste.ini:
1 | [composite:gnocchi+noauth] |
paste.app_factory 是一个应用的工厂函数,指明import对象的类型;值 gnocchi.rest.app:app_factory 指明具体加载的模块和方法。
1 | def _setup_app(root, conf, indexer, storage, not_implemented_middleware): |
我们知道,要运行一个python的web服务,需要两个条件:
- application
- wsgi server
这里通过加载pecan.make_app ,返回了一个application,并设置 hooks ,加载数据库连接等信息。
这里的 root 就是上面api-paste.ini中的root = gnocchi.rest.V1Controller
1 | class V1Controller(object): |
每次请求的路由的入口就是在这里了。具体怎么路由,可以看下之前写的分析pecan源码的文章。
简单看下监控数据存储的接口吧,POST /v1/batch/resources/metrics/measures?create_metrics=True
根据上面的路由转发,可以看到路径是V1Controller --> BatchController --> ResourcesBatchController --> ResourcesMetricsBatchController --> ResourcesMetricsMeasuresBatchController.post
1 | class ResourcesMetricsMeasuresBatchController(rest.RestController): |
这里主要是将发送过来的监控数据存进了 gnocchi 的 incoming storage
gnocchi-metricd
gnocchi 的metricd 服务是进行数据聚合,压缩,生成时间序列存储的。
入口:gnocchi/cli.py
1 | def metricd(): |
这里用到了cotyledon库,不是本文重点,简单说可以看下这四个类 MetricScheduler、MetricProcessor、MetricReporting、MetricJanitor 的 _run_job 方法,这是启动方法。
数据接收
1 | class MetricScheduler(MetricProcessBase): |
MetricScheduler 进行主要是从 gnocchi 的 incoming storage 去拉取数据,存进 queue,由于我这里用的是redis,所以进到RedisStorage;
1 | class MetricProcessor(MetricProcessBase): |
这里从 queue 中拉取数据,通过 process_background_tasks 处理:
1 | # gnocchi/storage/__init__.py |
这里主要做了几件事:
- 根据待处理的监控项集合,判断如果有已经删除的监控项,则删除对应incoming storage中的监控数据
- 遍历待处理的监控项列表,获取每个监控项在incoming storage中的监控数据列表,然后根据监控项及其待处理监控数据
调用_compute_and_store_timeseries方法来计算并存储时间序列
数据聚合
1 | def _compute_and_store_timeseries(self, metric, measures): |
步骤1. 对待处理监控数据按照时间从旧到新排序,获取监控项中聚合方法,采样间隔等信息
步骤2. 调用
_get_unaggregated_timeserie_and_unserialize方法获取未聚合的时间序列数据进行反序列化,来重新构建为新的时间序列,具体步骤如下
2.0. 先根据监控项id构建需要获取的对象名称,形如:gnocchi_01f0658b-f147-482b-bca9-f474a79320dc_none_v3
从ceph中读取该对象存储的值(是一个字符串) 2.1. 先解压从步骤0中读取的数据(实际是一个字符串),前面一半为时间,后面一半为时间对应的值
2.2. 解压的时间由于采用差值,所以累加计算每个时间;
2.3. 将时间列表,值列表来构建时间序列,然后根据block_size(实际是最大采样间隔)对序列计算出这个时间序列中最后一个数据,在一天之前的起始时间,以该时间为基础,对此时间序列进行切片,得到最终需要处理的时间序列
2.4. 用步骤3的时间序列,block_size等实例化并返回最终需要处理的BoundTimeSerie
步骤3 计算聚合后的时间序列,具体调用ts.set_values方法处理过程如下
3.1. 对给定的已经合并了待处理数据生成的时间序列和未聚合的时间序列的合并时间序列boundTimeSerie进行如下操作
3.2. 遍历归档策略,根据采样间隔,聚合方法:
计算每个boundTimeSerie聚合后的时间序列;
并对该聚合的时间序列分割,计算分割序列的偏移量和对应序列化的值;
根据偏移量,将序列化的值写入到对应的ceph对象
总结:步骤3实现了: 计算聚合后的时间序列,将聚合后的时间序列写入到ceph对象中
步骤4. 更新未聚合的时间序列,具体调用_store_unaggregated_timeserie方法处理过程如下
4.1. 对时间序列的索引进行numpy.diff的求差值操作,并
在所求的索引差值列表的最前面加上该时间序列的第一个值,
得到差值索引列表 4.2. 对差值索引列表的类型转换为uint64类型
4.3. 对时间序列的值列表类型转换为浮点型
4.4 对差值索引列表转换为字节 + 对时间序列的值列表转换为字节,
得到字符串 4.5. 对该字符串调用lz4.dumps进行压缩,返回该压缩后的字符串
4.6 构建类似gnocchi_01f0658b-f147-482b-bca9-f474a79320dc_none_v3的对象名称,
向该对象中写入未聚合的时间序列的压缩后的字符串
该字符串序列化前的前半部分为:时间序列索引,后半部分为时间序列值
步骤1. 对待处理监控数据按照时间从旧到新排序,获取监控项中聚合方法,采样间隔等信息
1 | def _compute_and_store_timeseries(self, metric, measures): |
步骤2. 调用_get_unaggregated_timeserie_and_unserialize方法获取未聚合的时间序列数据进行反序列化,来重新构建为新的时间序列,
1 | class CarbonaraBasedStorage(storage.StorageDriver): |
变量分析:
1 | (Pdb) p metric |
1 | class BoundTimeSerie(TimeSerie): |
步骤3. 计算聚合后的时间序列,具体调用ts.set_values方法处理过程如下
经过步骤2,我们得到了ts对象:
1 | """ |
1 | class BoundTimeSerie(TimeSerie): |
1 | class CarbonaraBasedStorage(storage.StorageDriver): |
步骤4. 更新未聚合的时间序列,具体调用_store_unaggregated_timeserie方法处理过程如下
1 | def _compute_and_store_timeseries(self, metric, measures): |
1 | # ts.serialize() |
参考:

