任何你的不足,在你成功的那刻,都会被人说为特色。所以,坚持做你自己,而不是在路上被别人修改的面目全非。
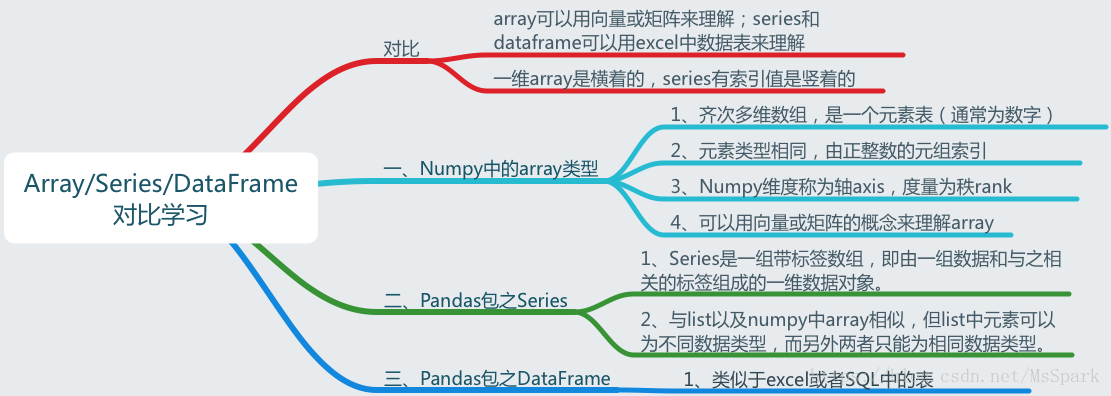
继续上篇的内容之前,先介绍下和今天有关系的两个库 numpy 、 pandas
工具
pandas
简介
Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
数据结构
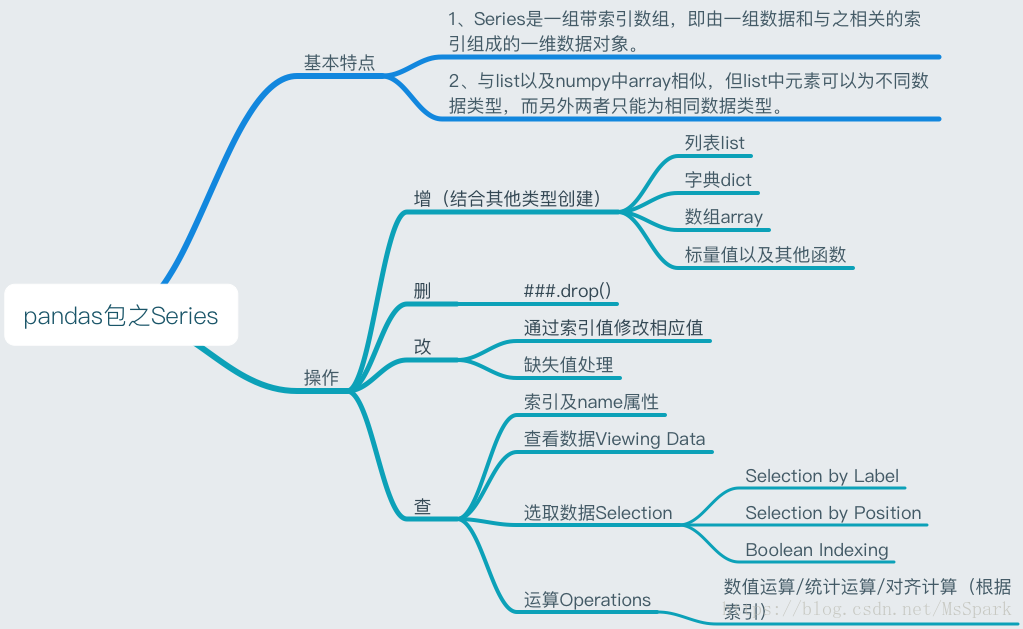
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。以下内容基本以这种结构为主。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。
Panel :三维的数组,可以理解为DataFrame的容器。
Pandas 有两种自己独有的基本数据结构。读者应该注意的是,它固然有着两种数据结构,因为它依然是 Python 的一个库,所以,Python 中有的数据类型在这里依然适用,也同样还可以使用类自己定义数据类型。只不过,Pandas 里面又定义了两种数据类型:Series 和 DataFrame,它们让数据操作更简单了。
使用 Series
创建 series
1 | #导入 Pandas 包 |
index及value属性
1 | # Series类型包括(index,values)两部分 |
1 | pandas.Index.is_monotonic # Alias for is_monotonic_increasing |
1 | pandas.Index.has_duplicates |
1 | pandas.Series.combine_first(other) |
获取数据
1 | #iloc通过位置获取数据 |
基本运算
1 | # 查看描述性统计数据 |
1 | # 数学运算 |
1 | # 对齐计算 |
缺失值处理
1 | #找出空/非空值 |
删除值
1 | dictSer3=dictSer3.drop('b') |
总结归纳:
使用 timestamp
Timestamp()
1 | import pandas as pd |
to_datetime()
pandas.to_datetime(arg,errors ='raise',utc = None,format = None,unit = None )
errors:三种取值,‘ignore’, ‘raise’, ‘coerce’,默认为raise。
‘raise’,则无效的解析将引发异常
‘coerce’,那么无效解析将被设置为NaT
‘ignore’,那么无效的解析将返回输入值
utc:布尔值,默认为none。返回utc即协调世界时。
format:格式化显示时间的格式。
unit:默认值为‘ns’,则将会精确到微妙,‘s’为秒。
1 | import pandas as pd |
numpy
Numpy(Numerical Python 的简称)时高性能科学计算和数据分析的基础包,提供了矩阵运算的功能。
相关链接Numpy官方推荐教程
Numpy具有以下几点能力:
- ndarry——一个具有向量算数运算和复杂广播能力的多位数组对象
- 用于对数组数据进行快速运算的标准数学函数
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具
- 非常有用的线性代数,傅立叶变换和随机数操作
- 用于继承c/c++和Fortran代码的工具
创建Numpy数组
1 | # 使用numpy.array()可直接导入数组或矩阵 |
获取与创建数组时设置纬度
1 | # reshape将当前一位数组设置成对应的m*n的矩阵 |
数组索引、切片、比较
1 | matrix = np.array([[1,2,3],[20,30,40]]) |
数组值的替换
值的替换在自然语言处理中很有用,例如我们在处理一个文本数组的时候,有几个数据元素是空,那么我们可以结合判断语句来获得是否为空的一个布尔数组,然后利用这个布尔数组进行元素替换
1 | matrix=np.array([['1','2',''],['3','4','5'],['5','6','']]) |
数据类型转换
初始化时设置数据类型用dtype
astype用于更改数据类型
1 | vector = np.array(['1','2','3']) |
统计计算方法
1 | sum |
计算差值
numpy.diff(a, n=1,axis=-1)
沿着指定轴计算第N维的离散差值
参数:
a:输入矩阵
n:可选,代表要执行几次差值
axis:默认是最后一个
示例:
1 | import numpy as np |
添加元素 insert
numpy.insert(arr, obj, values, axis=None)
第一个参数arr是一个数组,可以是一维的也可以是多维的,在arr的基础上插入元素
第二个参数obj是元素插入的位置
第三个参数values是需要插入的数值
第四个参数axis是指示在哪一个轴上对应的插入位置进行插入
1 | # 一维数组示例 |
多维数组可以看下 –> numpy.insert 详解
缓冲区读取
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
第一个参数 buffer :buffer_like:公开缓冲区接口的对象。
第二个参数 dtype :data-type, 可选:返回array的数据类型;默认值:float。
第三个参数 count :int, 可选:要阅读的条目数。-1表示缓冲区中的所有数据。
第四个参数 offset :int, 可选:从这个偏移量(以字节为单位)开始读取缓冲区;默认值:0。
此函数将缓冲区解释为一维数组。 暴露缓冲区接口的任何对象都用作参数来返回ndarray。
1 | import numpy as np |
计算给定轴上数组元素的累计和
numpy.cumsum(arr, axis=None, dtype=None, out=None)
第一个参数 arr : [数组]包含需要累计综合的数字的数组。如果arr不是数组,则尝试进行转换。
第二个参数 axis : 计算累计的轴,默认值是计算展平数组的综合。
- axis=0,按照行累加。
- axis=1,按照列累加。
- axis不给定具体值,就把numpy数组当成一个一维数组。
第三个参数 dtype : 返回数组的类型,以及与元素相乘的累加器的类型。如果未指定dtype,则默认为arr的dtype,除非arr的整数dtype的精度小于默认平台整数的精度。在这种情況下,将使用默认平台整数。
第四个参数 out :[ndarray,可选]将结果存储到的位置。
- 如果提供,则必須具有广播输入的形狀。
- 如果未提供或沒有,则返回新分配的数组。
返回 Return :除非指定out,否则将返回保存结果的新数组,在这种情況下将返回该数组。
1 | a = np.array([[1,2,3], [4,5,6]]) |
上述两个库的体量很大,这里只是简单介绍,有兴趣的同学可自行 google
struct
python中struct 模块用于python数据结构与C结构之间的相互转换,其中C结构是用一种格式化字符串表示的,学习struct 模块的难点就在这个格式化字符串上
常见方法
1 | # 常见方法 |
格式化串
格式化串的字符根据功能不同可以分为两类,一类用于控制字节顺序、大小及对齐(Byte Order, Size, and Alignment),另一类用于表示结构体的组成(Format Characters)。
Byte Order, Size, and Alignment
字节顺序对齐相关知识详见 C语言字节对齐问题详解(对齐、字节序、网络序等)
| 字符 | 字节序 | 大小 | 对齐方式 |
|---|---|---|---|
| @ | 原生 | 原生 | 原生 |
| = | 原生 | 标准 | 无 |
| < | 小端 | 标准 | 无 |
| > | 大端 | 标准 | 无 |
| ! | 网络字节序 | 标准 | 无 |
注:原生指使用本地机器的字节序、大小和对齐方式
这些字符出现在格式化字符串的开头,如果没有给出,默认为@,字节大小一列中的标准是指下面的 Format Characters。
Format Characters
| 格式 | C 类型 | Python 类型 | 标准大小 | 注释 |
|---|---|---|---|---|
x |
填充字节 | 无 | ||
c |
char |
长度为 1 的字节串 | 1 | |
b |
signed char |
整数 | 1 | (1), (2) |
B |
unsigned char |
整数 | 1 | (2) |
? |
_Bool |
bool | 1 | (1) |
h |
short |
整数 | 2 | (2) |
H |
unsigned short |
整数 | 2 | (2) |
i |
int |
整数 | 4 | (2) |
I |
unsigned int |
整数 | 4 | (2) |
l |
long |
整数 | 4 | (2) |
L |
unsigned long |
整数 | 4 | (2) |
q |
long long |
整数 | 8 | (2) |
Q |
unsigned long long |
整数 | 8 | (2) |
n |
ssize_t |
整数 | (3) | |
N |
size_t |
整数 | (3) | |
e |
(6) | 浮点数 | 2 | (4) |
f |
float |
浮点数 | 4 | (4) |
d |
double |
浮点数 | 8 | (4) |
s |
char[] |
字节串 | ||
p |
char[] |
字节串 | ||
P |
void * |
整数 | (5) |
序列化和反序列化
上篇我们说到 ceilometer-collector 会先将监控数据发给 gnocchi-api ,gnocchi-api 先和 mysql 即 index storage 中的 metric 进行对比,metric 不存在就创建,存在就更新,然后将监控数据 metric + measures 存进 redis 即 incoming storage,然后 gnocch-metricd 服务每隔 30s 到 redis 中拿取数据,进行处理,数据处理主要分为以下几步:
- 遍历 metrics ,通过每个 metric 的 id 从 redis 拿到相应的 measures
- 从 ceph 查询拿到该 metric 没有聚合过的时间序列进行反序列化(为什么会有未序列化的数据?)
- 根据给定的聚合方法,归档策略等信息,以及已经分组的时间序列,计算聚合后的时间序列,并将聚合后的时间序列写入到ceph的对象中
- 序列化没有聚合过的时间序列后,再压缩后存进 ceph (同2,为什么会有未序列化的数据?)
我们对上面的步骤进行拆解下,详细分析一下过程:
上面分析过了,到 _compute_and_store_timeseries 方法对 measures 进行排序之后,变量大概是这样的:
1 | """ |
下一步开始取出未聚合的时间序列进行反序列化,这里是与最后的 _store_unaggregated_timeserie 过程其实是相反的,一个是序列化,一个是反序列化。
1 | _SERIALIZATION_TIMESTAMP_VALUE_LEN = struct.calcsize("<Qd") # 16 |
序列化
根据上面的工具专栏介绍我们知道了 numpy 的一些用法,以此为基础分析:
1 | # 序列化 |
序列化的过程发生在存储未聚合的时间序列的数据的时候,一个 ts 类似是以下对象:
1 | """ |
反序列化
1 | # 反序列化 |
我们从 ceph 中拿到的一个解压后的字符串大概是这样的:
1 | \x00T\r\x15\xc4\xc7#\x16\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00\xec|o\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00\xec|o\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00"\xe23\x0e\x00\x00\x00\x00XG\xf8\r\x00\x00\x00\x00@Ys\x07\x00\x00\x00\x00\x18\xee\x84\x06\x00\x00\x00\x00\xb0\x8e\xf0\x1b\x00\x00\x00\x00@Ys\x07\x00\x00\x00\x00\xe2\x88\xc0\x06\x00\x00\x00\x00v\xbe7\x07\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xf0?\x00\x00\x00\x00\x00\x00\x00@\x00\x00\x00\x00\x00\x00\x08@\x00\x00\x00\x00\x00\x00\x10@\x00\x00\x00\x00\x00\x00\x14@\x00\x00\x00\x00\x00\x00\x18@\x00\x00\x00\x00\x00\x00\x1c@\x00\x00\x00\x00\x00\x00 @\x00\x00\x00\x00\x00\x00"@\x00\x00\x00\x00\x00\x00$@\x00\x00\x00\x00\x00\x00&@\x00\x00\x00\x00\x00\x00(@\x00\x00\x00\x00\x00\x00*@\x00\x00\x00\x00\x00\x00,@\x00\x00\x00\x00\x00\x00.@\x00\x00\x00\x00\x00\x000@\x00\x00\x00\x00\x00\x001@\x00\x00\x00\x00\x00\x002@\x00\x00\x00\x00\x00\x003@\x00\x00\x00\x00\x00\x004@\x00\x00\x00\x00\x00\x005@\x00\x00\x00\x00\x00\x006@\x00\x00\x00\x00\x00\x007@\x00\x00\x00\x00\x00\x008@\x00\x00\x00\x00\x00\x009@\x00\x00\x00\x00\x00\x00:@\x00\x00\x00\x00\x00\x00;@\x00\x00\x00\x00\x00\x00<@\x00\x00\x00\x00\x00\x00=@\x00\x00\x00\x00\x00\x00>@\x00\x00\x00\x00\x00\x00?@\x00\x00\x00\x00\x00\x00@@\x00\x00\x00\x00\x00\x80@@\x00\x00\x00\x00\x00\x00A@\x00\x00\x00\x00\x00\x80A@\x00\x00\x00\x00\x00\x00B@\x00\x00\x00\x00\x00\x80B@\x00\x00\x00\x00\x00\x00C@\x00\x00\x00\x00\x00\x80C@\x00\x00\x00\x00\x00\x00D@\x00\x00\x00\x00\x00\x80D@\x00\x00\x00\x00\x00\x00E@\x00\x00\x00\x00\x00\x80E@\x00\x00\x00\x00\x00\x00F@\x00\x00\x00\x00\x00\x80F@\x00\x00\x00\x00\x00\x00G@\x00\x00\x00\x00\x00\x80G@\x00\x00\x00\x00\x00\x00H@\x00\x00\x00\x00\x00\x80H@\x00\x00\x00\x00\x00\x00I@\x00\x00\x00\x00\x00\x80I@\x00\x00\x00\x00\x00\x00J@\x00\x00\x00\x00\x00\x80J@\x00\x00\x00\x00\x00\x00K@\x00\x00\x00\x00\x00\x80K@\x00\x00\x00\x00\x00\x00L@\x00\x00\x00\x00\x00\x80L@\x00\x00\x00\x00\x00\x00M@\x00\x00\x00\x00\x00\x80M@\x00\x00\x00\x00\x00\x00N@\x00\x00\x00\x00\x00\x80N@\x00\x00\x00\x00\x00\x00O@\x00\x00\x00\x00\x00\x80O@\x00\x00\x00\x00\x00\x00P@\x00\x00\x00\x00\x00@P@\x00\x00\x00\x00\x00\x80P@\x00\x00\x00\x00\x00\xc0P@\x00\x00\x00\x00\x00\x00Q@\x00\x00\x00\x00\x00@Q@\x00\x00\x00\x00\x00\x80Q@\x00\x00\x00\x00\x00\xc0Q@\x00\x00\x00\x00\x00\x00R@\x00\x00\x00\x00\x00@R@\x00\x00\x00\x00\x00\x80R@\x00\x00\x00\x00\x00\xc0R@\x00\x00\x00\x00\x00\x00S@\x00\x00\x00\x00\x00@S@\x00\x00\x00\x00\x00\x80S@\x00\x00\x00\x00\x00\xc0S@\x00\x00\x00\x00\x00\x00T@\x00\x00\x00\x00\x00@T@\x00\x00\x00\x00\x00\x80T@\x00\x00\x00\x00\x00\xc0T@\x00\x00\x00\x00\x00\x00U@\x00\x00\x00\x00\x00@U@\x00\x00\x00\x00\x00\x80U@\x00\x00\x00\x00\x00\xc0U@\x00\x00\x00\x00\x00\x00V@\x00\x00\x00\x00\x00@V@\x00\x00\x00\x00\x00\x80V@\x00\x00\x00\x00\x00\xc0V@\x00\x00\x00\x00\x00\x00W@\x00\x00\x00\x00\x00@W@\x00\x00\x00\x00\x00\x80W@\x00\x00\x00\x00\x00\xc0W@\x00\x00\x00\x00\x00\x00X@\x00\x00\x00\x00\x00@X@\x00\x00\x00\x00\x00\x80X@\x00\x00\x00\x00\x00\xc0X@\x00\x00\x00\x00\x00\x00Y@\x00\x00\x00\x00\x00@Y@\x00\x00\x00\x00\x00\x80Y@\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xc0Y@\x00\x00\x00\x00\x00@Z@\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80Z@\x00\x00\x00\x00\x00\x00\xf0? |
聚合和归档
聚合和归档操作发生在:
1 | with timeutils.StopWatch() as sw: |
合并时间序列
1 | class BoundTimeSerie(TimeSerie): |
ts的索引是时间,value是时间对应的值,上面的方法主要做了几个事情:
- 根据之前未聚合的时间序列最后一个时间lastTime为基点(这个未聚合的数据就是下面第四步将时间序列分割之后存进ceph的),计算出能够被最大采样间隔(例如86400)整除且最接近lasTtime的时间作为最近的起始时间firstTime,然后从待处理监控数据列表中过滤出时间 >= firstTime的待处理监控数据,太老的数据直接丢弃;
- 将待处理的监控数据(有时间,值的元组组成的列表),构建为待处理时间序列,并检查重复和是否是单调的,然后用原来未聚合的时间序列和当前待处理时间序列进行合并操作,得到新生成的时间序列
- 调用
_map_add_measures聚合归档 - 对时间序列进行分割,之后便是调用
self._store_unaggregated_timeserie(metric, ts.serialize()),将分割后的时间序列经过序列化和压缩后存进ceph,用于下一次的计算。
归档聚合
1 | current_first_block_timestamp = ts.first_block_timestamp() # 这个ts是未聚合的时间序列 |
- BoundTimeSerie 继承 TimeSerie,这里的first就是第一个索引值,我们知道 ts 是pandas.series对象,包括索引和值,索引是时间,值是时间对应的值,而 measures 是
[(Timestamp('2018-04-19 04:21:08.054995'), 4.799075611984741)]这样的对象,这里就是比较新生成的时间序列和从redis取的当前待处理时间序列,取出最大时间,接着计算出新生成的时间序列的第一个时间和需要计算的point; - 然后遍历归档策略:
- 先根据采样间隔和上步生成的最大边界的时间,算出这个间隔的另一个时间边界,返回一个 GroupedTimeSeries 对象,这个对象里面有很多的聚合方法,mean、min、max等。
- 然后再遍历聚合方法,通过
_add_measures(聚合方法,归档策略,metric指标,ts(GroupedTimeSeries对象),未聚合的时间序列的第一个时间戳,聚合后的时间序列的第一个时间戳)对事件序列进行聚合计算存进 ceph:
1 | class AggregatedTimeSerie(TimeSerie): |
definition样例:
[{‘points’: 300, ‘granularity’: 300.0, ‘timespan’: 90000.0}, {‘points’: 100, ‘granularity’: 900.0, ‘timespan’: 90000.0}, {‘points’: 100, ‘granularity’: 7200.0, ‘timespan’: 720000.0}, {‘points’: 200, ‘granularity’: 86400.0, ‘timespan’: 17280000.0}]
一个d即archive_policy_def:{‘points’: 300, ‘granularity’: 300.0, ‘timespan’: 90000.0},代表计算间隔300s,采集300个点,间隔300*300=90000
步骤一:从 GroupedTimeSeries 取出具体的聚合方法,实例化 AggregatedTimeSerie 类对象,返回 ts
1
2
3
4
5
6
7
8
9
10
11
12
13
14ts = carbonara.AggregatedTimeSerie.from_grouped_serie(
grouped_serie, archive_policy_def.granularity,
aggregation, max_size=archive_policy_def.points)
class AggregatedTimeSerie(TimeSerie):
_AGG_METHOD_PCT_RE = re.compile(r"([1-9][0-9]?)pct")
def from_grouped_serie(cls, grouped_serie, sampling, aggregation_method,
max_size=None):
agg_name, q = cls._get_agg_method(aggregation_method)
return cls(sampling, aggregation_method,
ts=cls._resample_grouped(grouped_serie, agg_name,
q),
max_size=max_size)步骤二:拿出当前metric在ceph中的字符串(待分析)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class CephStorage(_carbonara.CarbonaraBasedStorage):
WRITE_FULL = False
def _list_split_keys_for_metric(self, metric, aggregation, granularity,
version=None):
with rados.ReadOpCtx() as op:
omaps, ret = self.ioctx.get_omap_vals(op, "", "", -1)
try:
self.ioctx.operate_read_op(
op, self._build_unaggregated_timeserie_path(metric, 3))
except rados.ObjectNotFound:
raise storage.MetricDoesNotExist(metric)
if ret == errno.ENOENT:
raise storage.MetricDoesNotExist(metric)
keys = set()
for name, value in omaps:
meta = name.split('_')
if (aggregation == meta[3] and granularity == float(meta[4])
and self._version_check(name, version)):
keys.add(meta[2])
return keys步骤三:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17if archive_policy_def.timespan:
oldest_point_to_keep = ts.last - datetime.timedelta(
seconds=archive_policy_def.timespan)
oldest_key_to_keep = ts.get_split_key(oldest_point_to_keep)
oldest_key_to_keep_s = str(oldest_key_to_keep)
for key in list(existing_keys):
# NOTE(jd) Only delete if the key is strictly inferior to
# the timestamp; we don't delete any timeserie split that
# contains our timestamp, so we prefer to keep a bit more
# than deleting too much
if key < oldest_key_to_keep_s:
self._delete_metric_measures(
metric, key, aggregation,
archive_policy_def.granularity)
existing_keys.remove(key)
else:
oldest_key_to_keep = carbonara.SplitKey(0, 0)步骤四:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19if need_rewrite:
previous_oldest_mutable_key = str(ts.get_split_key(
previous_oldest_mutable_timestamp))
oldest_mutable_key = str(ts.get_split_key(
oldest_mutable_timestamp))
if previous_oldest_mutable_key != oldest_mutable_key:
for key in existing_keys:
if previous_oldest_mutable_key <= key < oldest_mutable_key:
LOG.debug(
"Compressing previous split %s (%s) for metric %s",
key, aggregation, metric)
# NOTE(jd) Rewrite it entirely for fun (and later for
# compression). For that, we just pass None as split.
self._store_timeserie_split(
metric, carbonara.SplitKey(
float(key), archive_policy_def.granularity),
None, aggregation, archive_policy_def,
oldest_mutable_timestamp)步骤五:
1
2
3
4
5
6
7
8for key, split in ts.split():
if key >= oldest_key_to_keep:
LOG.debug(
"Storing split %s (%s) for metric %s",
key, aggregation, metric)
self._store_timeserie_split(
metric, key, split, aggregation, archive_policy_def,
oldest_mutable_timestamp)
总结
1 | 处理逻辑: |
基于gnocchi的时间序列算法demo实现
1 | #!/usr/bin/env python |
参考:
struct — 将字节串解读为打包的二进制数据
相近文章:

