生命只有走出来的精彩,沒有等待出来的辉煌;埋怨,只是一种懦弱的表现;努力,才是人生的态度!实力代表尊严!
相信大家在学习web开发的过程中一定会遇到 cgi、 wsgi 之类的名词,然后看着他们十分相似的解释估计还没开始写代码就晕了,这都什么鬼?
下面我们就来认识一下
CGI(Common Gateway Inteface): 字面意思就是通用网关接口,我觉得之所以看字面意思跟没看一样是因为这个称呼本身很学术,所以对于通俗的理解就存在一定困难,这里我觉得直接把 Gateway 当作 server 理解就好。
它是外部应用程序与Web服务器之间的接口标准
意思就是它用来规定一个程序该如何与web服务器程序之间通信从而可以让这个程序跑在web服务器上。当然,CGI 只是一个很基本的协议,在现代常见的服务器结构中基本已经没有了它的身影,更多的则是它的扩展和更新。
FastCGI: CGI的一个扩展, 提升了性能,废除了 CGI fork-and-execute (来一个请求 fork 一个新进程处理,处理完再把进程 kill 掉)的工作方式,转而使用一种长生存期的方法,减少了进程消耗,提升了性能。
这里 FastCGI 就应用于前端 server(nginx)与后端 server(uWSGI)的通信中,制定规范等等,让前后端服务器可以顺利理解双方都在说什么(当然 uWSGI 本身并不用 FastCGI, 它有另外的协议)
WSGI:全称是Web Server Gateway Interface,WSGI不是服务器,python模块,框架,API或者任何软件,只是一种规范,描述web server如何与web application通信的规范。server和application的规范在PEP 3333中有具体描述。要实现WSGI协议,必须同时实现web server和web application,当前运行在WSGI协议之上的web框架有Bottle, Flask, Django。
uwsgi:与WSGI一样是一种通信协议,是uWSGI服务器的独占协议,用于定义传输信息的类型(type of information),每一个uwsgi packet前4byte为传输信息类型的描述,与WSGI协议是两种东西,据说该协议是fcgi协议的10倍快。
uWSGI:是一个web服务器,实现了WSGI协议、uwsgi协议、http协议等。
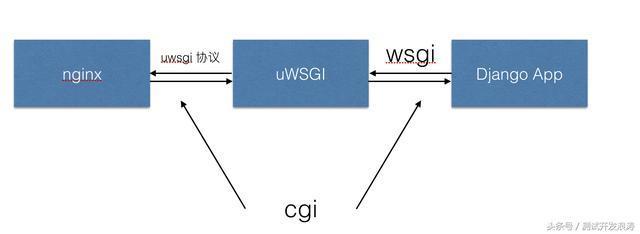
对于 CGI ,我认为在 CGI 制定的时候也许没有考虑到现代的架构,所以他只是一个通用的规范,而后来的 WSGI 也好 Fastcgi 也好等等这些都是在 CGI 的基础上扩展并应用于现代Web Server 不同地方的通信规范, 所以我在图中将 CGI 标注在整个流程之上。
做为一个 Python Web 开发者,相信以上流程我们最关注的莫过于 WSGI 这里所做的事,了解熟悉这里的规范不仅可以让我们更快速的开发 Web 应用同时我们也可以自己实现一个后端 Server 。
WSGI 初识
OK,回头题目,我们先来想一下,当我们部署完一个应用程序,浏览网页时具体的过程是怎样的呢?
- 首先我们得有一个 Web 服务器来处理 HTTP 协议的内容;
- Web 服务器获得客户端的请求,交给应用程序,应用程序可以是各种语言编写的(Java, PHP, Python, Ruby等);
- 应用程序处理完,返回给 Web 服务器;
- 这时 Web 服务器再返回给客户端。
那么,要采用这种方案,Web服务器和应用程序之间就要知道如何进行交互。为了定义Web服务器和应用程序之间的交互过程,就形成了很多不同的规范。最早出现的是 CGI,后来又出现了改进 CGI 性能的FasgCGI,Java 专用的 Servlet 规范,Python 专用的 WSGI 规范等等。提出这些规范的目的就是为了定义统一的标准,提升程序的可移植性。在WSGI规范的最开始的PEP 3333中一开始就描述了为什么需要WSGI规范。
所以我们再看下上面的定义,WSGI就是一个python专用的规范,定义了Web服务器如何与Python应用程序进行交互,使得使用Python写的Web应用程序可以和Web服务器对接起来。这里的Python应用程序,就是你写的django,Flask等代码。但是为什么我们调试的时候,可以直接起django或者flask框架进行调试呢,因为在这两个框架里面都封装了好了简单的web服务器,但是也只是建议用于平时调试使用,性能较差,在生产环境还是不要用了,那么我们生产环境用什么呢?uWSGI就登场啦。
uWSGI、uwsgi初识
uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换。该协议据说性能非常高,而且内存占用率低,为mod_wsgi的一半左右,我没有实测过。
注意,这里出现了uwsgi,uwsgi同WSGI一样是一种通信协议,该协议是一个uWSGI服务器自有的协议,它用于定义传输信息的类型(type of information),每一个uwsgi packet前4byte为传输信息类型描述,它与WSGI相比是两样东西,据说该协议是fcgi协议的10倍快。
除了uWSGI之外,Gunicorn也是实现了WSGI server协议的服务器,这个服务器后面有时间再讲。
Python标准库提供独立WSGI服务器称为
wsgiref。
uWSGI 作用:
- uWSGI旨在为部署分布式集群的网络应用开发一套完整的解决方案
- 主要面向web及其标准服务。由于其
可扩展性,能够被无限制的扩展用来支持更多平台和多语言 - 实现了
WSGI协议、uwsgi协议等 uWSGI服务器自己实现了基于uwsgi协议的server部分,我们只需要在uwsgi的配置文件中指定application的地址,uWSGI就能直接和应用框架中的WSGI application通信。- uWSGI的主要特点是:
- 超快的
性能低内存占用多app管理- 详尽的
日志功能(可以用来分析app的性能和瓶颈)高度可定制(内存大小限制,服务一定次数后重启等)
看到这里,问题又来了,既然 uWSGI 已经是服务器了,为啥有时还需要 Nginx 呢?而且,对于 Nginx 来说,是无法与直接跟flask等application做通信的,需要借用wsgi server。所以这里就引出了两种结构:
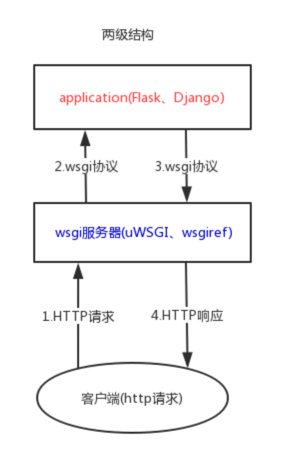
两级结构
在这种结构里,uWSGI作为服务器,它用到了HTTP协议以及wsgi协议,flask应用作为application,实现了wsgi协议。当有客户端发来请求,uWSGI接受请求,调用flask app得到相应,之后相应给客户端。
上面我们说过,Flask等web框架会自己附带一个wsgi服务器(这就是flask应用可以直接启动的原因),但是这只是在开发阶段用到的,在生产环境是不够用的,所以用到了uwsgi这个性能高的wsgi服务器。
以下是他们的结构图:
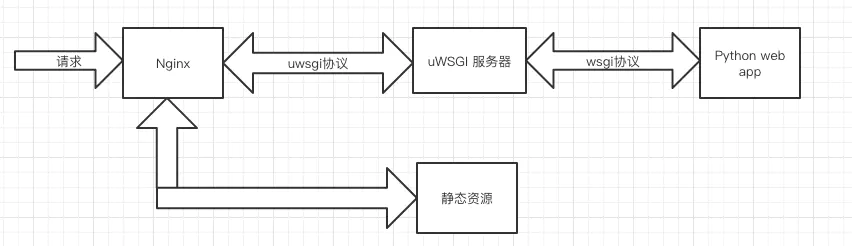
三级结构
这种结构里,uWSGI作为中间件,它用到了uwsgi协议(与nginx通信),wsgi协议(调用Flask app)。当有客户端发来请求,nginx先做处理(静态资源是nginx的强项),无法处理的请求交给(uWSGI),最后也是nginx回复给客户端。
以下是他们的结构图:
多了一层反向代理有什么好处?
- 提高web server性能(uWSGI处理静态资源不如nginx;nginx会在收到一个完整的http请求后再转发给wWSGI)
- nginx可以做负载均衡(前提是有多个服务器),保护了实际的web服务器(客户端是和nginx交互而不是uWSGI)
记得以前uwsgi没名气的时候,我们都在使用apache + mode_wsgi模式,apache也无法直接跟tornado通信,是借用mod_wsgi把torando做成了unix socket服务,说白了也是启动了一个服务,靠apache来转发。
所以 nginx、apache 在这里只是启动了proxy的作用。
WSGI的优点、缺点是什么?
优点:多样的部署选择和组件之间的高度解耦
由于上面提到的高度解耦特性,理论上,任何一个符合WSGI规范的App都可以部署在任何一个实现了WSGI规范的Server上,这给Python Web应用的部署带来了极大的灵活性。
Flask自带了一个基于Werkzeug的调试用服务器。根据Flask的文档,在生产环境不应该使用内建的调试服务器,而应该采取以下方式之一进行部署:
- GUNICORN
- uWSGI
缺点:忙吹一波,无
WSGI 实现
上面说了,WSGI 主要是两层,服务器(server) 和 应用程序(application),网上查资料,有的人也说是三层,多了层中间键(middleware),但其实并不准确,因为middleware对服务器程序和应用是透明的,也就是说,服务器程序以为它就是应用程序,而应用程序以为它就是服务器。这就告诉我们,middleware需要把自己伪装成一个服务器,接受应用程序,调用它,同时middleware还需要把自己伪装成一个应用程序,传给服务器程序,所以本质上应该还是两层。
其实无论是服务器程序,middleware 还是应用程序,都在服务端,为客户端提供服务,之所以把他们抽象成不同层,就是为了控制复杂度,使得每一次都不太复杂,各司其职。
- 服务器方:从底层解析http请求,然后调用应用程序,给应用程序提供(环境信息-environ)和(回调函数-start_respnse), 这个回调函数是用来将应用程序设置的http header和status等信息传递给服务器方.
- 应用程序:用来生成返回的header,body和status,以便返回给服务器方。
- 中间键:有些功能可能介于服务器程序和应用程序之间,例如,服务器拿到了客户端请求的URL, 不同的URL需要交由不同的函数处理,这个功能叫做 URL Routing,这个功能就可以放在二者中间实现,这个中间层就是 middleware。
WSGI把来自socket的数据包解析为http格式,然后进而变化为environ变量,这environ变量里面有wsgi本身的信息(比如 host, post,进程模式等),还有client的header及body信息。start_respnse是一个回调函数,必须要附带两个参数,一个是status(http状态),response_headers(响应的header头信息)。
像flask、django、tornado都会暴露WSGI协议入口,我们只需要自己实现WSGI协议,wsgi server然后给flask传递environ,及start_response, 等到application返回值之后,我再socket send返回客户端。
application
基本实现
一个基本的wsgi应用,需要实现以下三个功能:
必须是一个可调用的对象
在Python中:
- 可以是函数
- 可以是一个实例,它的类实现了
__call__方法 - 可以是一个类,这时候,用这个类生成实例的过程就相当于调用这个类
接收两个必选参数environ、start_response,以及一个可选参数exc_info。参数名不是固定的,这就意味着你必须使用位置参数而非关键字参数(这应该是用来约束wsgi服务器的)
environ存放CGI规定的变量一及别的变量。
start_response 是一个可调用对象,通过类似start_response(‘200 OK’,[(‘Content-Type’,’text/html’))来发送http的相应头部。
exc_info 只有start_response()被错误处理程序调用时,这个参数才会提供,并且是有应用对象提供。
示例:
如果这个对象是函数的话,它看起来要是这个样子:
1
2
3# callable function
def application(environ, start_response):
pass如果这个对象是一个类的话,它看起来是这个样子:
1
2
3
4# callable class
class Application:
def __init__(self, environ, start_response):
pass如果这个对象是一个类的实例,那么,这个类看起来是这个样子:
1
2
3
4# callable object
class ApplicationObj:
def __call__(self, environ, start_response):
pass
可调用对象要返回一个值,这个值是可迭代的。
这样的话,前面的三个例子就变成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21HELLO_WORLD = b"Hello world!\n"
# callable function
def application(environ, start_response):
return [HELLO_WORLD]
# callable class
class Application:
def __init__(self, environ, start_response):
pass
def __iter__(self):
yield HELLO_WORLD
# callable object
class ApplicationObj:
def __call__(self, environ, start_response):
return [HELLO_WORLD]你可能会说,不是啊,我们平时写的web程序不是这样啊。 比如如果使用web.py框架的话,一个典型的应用可能是这样的:
1
2
3class hello:
def GET(self):
return 'Hello, world!'这是由于框架已经把WSGI中规定的一些东西封装起来了,我们平时用框架时,看不到这些东西,只需要直接实现我们的逻辑,再返回一个值就好了。其它的东西框架帮我们做好了。这也是框架的价值所在,把常用的东西封装起来,让使用者只需要关注最重要的东西。
当然,WSGI关于应用程序的规定不只这些,但是现在,我们只需要知道这些就足够了。下面,再介绍服务器程序。
environ参数
在第二点我们提到了 environ参数,单独介绍下
environ参数是一个Python的字典,里面存放了所有和客户端相关的信息,这样application对象就能知道客户端请求的资源是什么,请求中带了什么数据等。environ字典包含了一些CGI规范要求的数据,以及WSGI规范新增的数据,还可能包含一些操作系统的环境变量以及Web服务器相关的环境变量。我们来看一些environ中常用的成员:
首先是CGI规范中要求的变量:
REQUEST_METHOD: 请求方法,是个字符串,’GET’, ‘POST’等
SCRIPT_NAME: HTTP请求的path中的用于查找到application对象的部分,比如Web服务器可以根据path的一部分来决定请求由哪个virtual host处理
PATH_INFO: HTTP请求的path中剩余的部分,也就是application要处理的部分
QUERY_STRING: HTTP请求中的查询字符串,URL中?后面的内容
CONTENT_TYPE: HTTP headers中的content-type内容
CONTENT_LENGTH: HTTP headers中的content-length内容
SERVER_NAME和SERVER_PORT: 服务器名和端口,这两个值和前面的SCRIPT_NAME, PATH_INFO拼起来可以得到完整的URL路径
SERVER_PROTOCOL: HTTP协议版本,HTTP/1.0或者HTTP/1.1
HTTP_: 和HTTP请求中的headers对应。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16REQUEST_METHOD = 'GET'
SCRIPT_NAME = ''
PATH_INFO = '/xyz'
QUERY_STRING = 'abc'
CONTENT_TYPE = 'text/plain'
CONTENT_LENGTH = ''
SERVER_NAME = 'minix-ubuntu-desktop'
SERVER_PORT = '8000'
SERVER_PROTOCOL = 'HTTP/1.1'
HTTP_ACCEPT = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
HTTP_ACCEPT_ENCODING = 'gzip,deflate,sdch'
HTTP_ACCEPT_LANGUAGE = 'en-US,en;q=0.8,zh;q=0.6,zh-CN;q=0.4,zh-TW;q=0.2'
HTTP_CONNECTION = 'keep-alive'
HTTP_HOST = 'localhost:8000'
HTTP_USER_AGENT = 'Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36'
WSGI规范中还要求environ包含下列成员:
wsgi.version:表示WSGI版本,一个元组(1, 0),表示版本1.0
wsgi.url_scheme:http或者https
wsgi.input:一个类文件的输入流,application可以通过这个获取HTTP request body
wsgi.errors:一个输出流,当应用程序出错时,可以将错误信息写入这里
wsgi.multithread:当application对象可能被多个线程同时调用时,这个值需要为True
wsgi.multiprocess:当application对象可能被多个进程同时调用时,这个值需要为True
wsgi.run_once:当server期望application对象在进程的生命周期内只被调用一次时,该值为True
示例:
1
2
3
4
5
6
7
8wsgi.errors = <open file '<stderr>', mode 'w' at 0xb735f0d0>
wsgi.file_wrapper = <class wsgiref.util.FileWrapper at 0xb70525fc>
wsgi.input = <socket._fileobject object at 0xb7050e6c>
wsgi.multiprocess = False
wsgi.multithread = True
wsgi.run_once = False
wsgi.url_scheme = 'http'
wsgi.version = (1, 0)
上面列出的这些内容已经包括了客户端请求的所有数据,足够application对象处理客户端请求了。
start_resposne参数
start_response是一个可调用对象,接收两个必选参数和一个可选参数:
- status: 一个字符串,表示HTTP响应状态字符串
- response_headers: 一个列表,包含有如下形式的元组:(header_name, header_value),用来表示HTTP响应的headers
- exc_info(可选): 用于出错时,server需要返回给浏览器的信息
当application对象根据environ参数的内容执行完业务逻辑后,就需要返回结果给server端。我们知道HTTP的响应需要包含status,headers和body,所以在application对象将body作为返回值return之前,需要先调用start_response(),将status和headers的内容返回给server,这同时也是告诉server,application对象要开始返回body了。
application对象的返回值
application对象的返回值用于为HTTP响应提供body,如果没有body,那么可以返回None。如果有body的化,那么需要返回一个可迭代的对象。server端通过遍历这个可迭代对象可以获得body的全部内容。
application demo
PEP-3333中有一个application的实现demo,我把它再简化之后如下:
1 | def simple_app(environ, start_response): |
可以将这段代码和前面的说明对照起来理解。
再来几个不同使用方式的示例:
1 | # hello.py |
1 | # 实现__call__方法的类的实例变量 WSGI服务器调用的对象是app1() |
1 | # 迭代法 WSGI服务器调用的对象是app2 |
这三种写法不同,但效果是一致的。
看起来很简单,那么怎么调用呢?这两个参数又是怎么提供呢?答案在下边。
server
服务器程序会在每次客户端的请求传来时,调用我们写好的应用程序,并将处理好的结果返回给客户端。
一个简单的服务器程序大概是这样子的:
1 | def run(application): |
status: 表示 HTTP 状态码,例如 “200 OK”, “404 Not Found”,它们在 RFC 2616中定义,status禁止包含控制字符。
response_headers: 是一个列表,列表项是一个二元组: (header_name, heaer_value) , 每个 header_name 都必须是 RFC 2616 4.2 节中定义的HTTP 头部名。header_value 禁止包含控制字符。
exc_info:
这是一个可选参数,它必须和Python的 sys.exc_info()返回的数据有相同类型。当处理请求的过程遇到错误时,这个参数会被设置,同时调用 start_response。如果提供了exc_info,但是HTTP headers 还没有输出,那么 start_response需要将当前存储的 HTTP response headers替换成一个新值。但是,如果提供了exc_info,同时 HTTP headers已经输出了,那么 start_response 必须 raise 一个 error。禁止应用程序处理 start_response raise出的 exceptions,应该交给服务器程序处理。
当且仅当提供 exc_info参数时,start_response才可以被调用多于一次。换句话说,要是没提供这个参数,start_response在当前应用程序中调用后,禁止再调用。
为了避免循环引用,start_response实现时需要保证 exc_info在函数调用后不再包含引用。 也就是说start_response用完 exc_info后,需要保证执行一句
2
>
>
> 这可以通过 try/finally实现。
这里可以看出服务器程序是如何与应用程序配合完成用户请求的。
WSGI规定了应用程序需要是一个可调用对象,有两个参数,返回一个可迭代对象。在 服务器 程序中,针对这几个规定,做了以下几件事:
- 把应用程序需要的两个参数设置好
- 调用应用程序
- 迭代访问应用程序的返回结果,并将其传回客户端
Python自己实现了一个WSGI服务器,名为wsgiref,怎么使用呢?见代码:
1 | # ser.py 同hello.py同一层 |
你可以从中发现,应用程序需要的两个参数,一个是一个dict对象,一个是函数。它们到底有什么用呢?这都不是我们现在应该关心的,现在只需要知道,服务器程序大概做了什么事情就好了,后面,我们会深入讨论这些细节。
middleware
WSGI Middleware(中间件)也是WSGI规范的一部分。上面我们已经说明了WSGI的两个角色:server和application。那么middleware是一种运行在server和application中间的应用(一般都是Python应用)。middleware同时具备server和application角色,对于server来说,它是一个application;对于application来说,它是一个server。middleware并不修改server端和application端的规范,只是同时实现了这两个角色的功能而已。
我们可以通过下图来说明middleware是如何工作的:
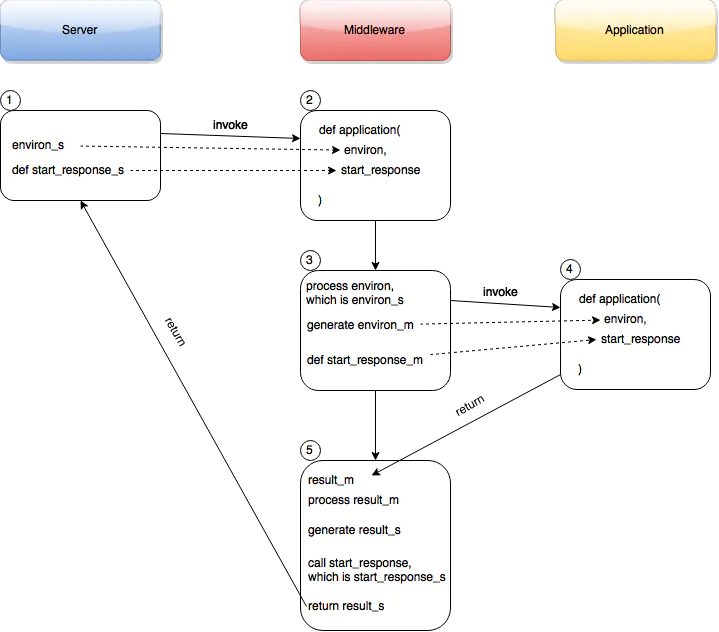
上图中最上面的三个彩色框表示角色,中间的白色框表示操作,操作的发生顺序按照1 ~ 5进行了排序,我们直接对着上图来说明middleware是如何工作的:
- Server收到客户端的HTTP请求后,生成了
environ_s,并且已经定义了start_response_s。 - Server调用Middleware的application对象,传递的参数是
environ_s和start_response_s。 - Middleware会根据
environ执行业务逻辑,生成environ_m,并且已经定义了start_response_m。 - Middleware决定调用Application的application对象,传递参数是
environ_m和start_response_m。Application的application对象处理完成后,会调用start_response_m并且返回结果给Middleware,存放在result_m中。 - Middleware处理
result_m,然后生成result_s,接着调用start_response_s,并返回结果result_s给Server端。Server端获取到result_s后就可以发送结果给客户端了。
从上面的流程可以看出middleware应用的几个特点:
- Server认为middleware是一个application。
- Application认为middleware是一个server。
- Middleware可以有多层。
因为Middleware能过处理所有经过的request和response,所以要做什么都可以,没有限制。比如可以检查request是否有非法内容,检查response是否有非法内容,为request加上特定的HTTP header等,这些都是可以的。
下面,我们看看middleware大概是什么样子的。
1 | # URL Routing middleware |
函数 midware_app就是一个简单的middleware:对服务器而言,它是一个应用程序,是一个可调用对象, 有两个参数,返回一个可调用对象。对应用程序而言,它是一个服务器,为应用程序提供了参数,并且调用了应用程序。
另外,这里的urlrouting函数,相当于一个函数生成器,你给它不同的 url-app 映射关系,它会生成相应的具有 url routing功能的 middleware。
WSGI的实现和部署
要使用WSGI,需要分别实现server角色和application角色。
Application端的实现一般是由Python的各种框架来实现的,比如Django, web.py等,一般开发者不需要关心WSGI的实现,框架会会提供接口让开发者获取HTTP请求的内容以及发送HTTP响应。
Server端的实现会比较复杂一点,这个主要是因为软件架构的原因。一般常用的Web服务器,如Apache和nginx,都不会内置WSGI的支持,而是通过扩展来完成。比如Apache服务器,会通过扩展模块mod_wsgi来支持WSGI。Apache和mod_wsgi之间通过程序内部接口传递信息,mod_wsgi会实现WSGI的server端、进程管理以及对application的调用。Nginx上一般是用proxy的方式,用nginx的协议将请求封装好,发送给应用服务器,比如uWSGI,应用服务器会实现WSGI的服务端、进程管理以及对application的调用。
如果你仅仅想简单了解一下WSGI是什么,相信到这里,你差不多明白了
如果想要了解更多的内容,可以看下 PEP3333 。
server 实现
1 | import socket |
app 实现
1 | from flask import Flask |
运行
1 | python webserver2.py flaskapp:app |
Gunicorn与uWSGI
perfork
perfork是一种服务端编程模型, Nginx, Gunicorn, uWSGI都是这种模型的实现, 简单的说perfok就是master进程启动注册一堆信号处理函数, 创建listen socket fd, fork出多个worker子进程, 子进程执行accept循环处理请求(这里简化模型, 当然也可以用select, epoll多路复用), master进程只负责监控worker进程状态, 通过pipeline通信来控制worker进程.
perfork模型使用master进程来监控worker进程状态, 避免了我们使用supervisor来监控进程, 还支持多种信号来控制worker的数量, 使得CPU能充分得到利用, 多个worker进程监听同一端口, 可以配置reuse_port参数在worker进程间负载均衡.
Gunicorn与uWSGI都是基于perfork模型的WSGI服务器。
Gunicorn
Gunicorn是使用Python实现的WSGI服务器, 直接提供了http服务, 并且在woker上提供了多种选择, gevent, eventlet这些都支持, 在多worker最大化里用CPU的同时, 还可以使用协程来提供并发支撑, 对于网络IO密集的服务比较有利.
同时Gunicorn也很容易就改造成一个TCP的服务, 比如doge重写worker类, 在针对长连接的服务时, 最好开启reuse_port, 避免worker进程负载不均。
uWSGI
不同于Gunicorn, uWSGI是使用C写的, 它的socket fd创建, worker进程的启动都是使用C语言系统接口来实现的, 在worker进程处理循环中, 解析了http请求后, 使用python的C接口生成environ对象, 再把这个对象作为参数塞到暴露出来的WSGI application函数中调用. 而这一切都是在C程序中进行, 只是在处理请求的时候交给python虚拟机调用application. 完全使用C语言实现的好处是性能会好一些.
除了支持http协议, uWSGI还实现了uwsgi协议, 一般我们会在uWSGI服务器前面使用Nginx作为负载均衡, 如果使用http协议, 请求在转发到uWSGI前已经在Nginx这里解析了一遍, 转发到uWSGI又会重新解析一遍. uWSGI为了追求性能, 设计了uwsgi协议, 在Nginx解析完以后直接把解析好的结果通过uwsgi协议转发到uWSGI服务器, uWSGI拿到请求按格式生成environ对象, 不需要重复解析请求. 如果用Nginx配合uWSGI, 最好使用uwsgi协议来转发请求.
除了是一个WSGI服务器, uWSGI还是一个开发框架, 它提供了缓存, 队列, rpc等等功能, 在github找找就会发现有人用它的缓存写了一个Django cache backend, 用它的队列实现异步任务这些东西, 但是用了这些东西技术栈也就跟uWSGI绑定在一起, 所以一般也只是把uWSGI当作WSGI服务器来用。
Nginx
使用多个进程监听同一端口就绕不开惊群这个话题, fork子进程, 子进程共享listen socket fd, 多个子进程同时accept阻塞, 在请求到达时内核会唤醒所有accept的进程, 然而只有一个进程能accept成功, 其它进程accept失败再次阻塞, 影响系统性能, 这就是惊群. Linux 2.6内核更新以后多个进程accept只有一个进程会被唤醒, 但是如果使用epoll还是会产生惊群现象.
Nginx为了解决epoll惊群问题, 使用进程间互斥锁, 只有拿到锁的进程才能把listen fd加入到epoll中, 在accept完成后再释放锁.
但是在高并发情况下, 获取锁的开销也会影响性能, 一般会建议把锁配置关掉. 直到Nginx 1.9.1更新支持了socket的SO_REUSEPORT选项, 惊群问题才算解决, listen socket fd不再是在master进程中创建, 而是每个worker进程创建一个通过SO_REUSEPORT 选项来复用端口, 内核会自行选择一个fd来唤醒, 并且有负载均衡算法.
Gunicorn与uWSGI都支持reuse_port选项, 在使用时可以通过压测来评估一下reuse_port是否能提升性能.
一般我们会在Gunicorn/uWSGI前面再加一层Nginx, 这样做的原因有一下几点:
- 做负载均衡
- 静态文件服务器
- 更安全
- 扛并发
参考:

