真正的坚强,是属于那些夜晚在被窝里哭泣,而白天却若无其事的人。未曾深夜痛哭过的人,不足以谈论人生。
基本概述
我们先从应用的角度来看详细的介绍一下alertmanager以下简称am,以下是官方文档介绍。
The Alertmanager handles alerts sent by client applications such as the Prometheus server. It takes care of deduplicating, grouping, and routing them to the correct receiver integrations such as email, PagerDuty, or OpsGenie. It also takes care of silencing and inhibition of alerts.
翻译一下就是,负责处理接受client(例如prometheus)发送的告警消息,包括重复告警的发送、聚合、发给相关人员,并且支持多种方式例如email或者pagerduty这种第三方通知告警平台,同时他还提供了静音以及告警抑制的功能。
这些功能基本涵盖了目前各大公司的告警痛点,重复告警(告警发生了但是一直也没人处理)、告警风暴(某次版本上线导致的大量服务机器指标异常)、告警信息重复(例如机器宕机之后又收到了网络不通的告警)。
这里注意下,prometheus族包括am他们的实现思路都是基于label来做的,后面会从代码层面详细介绍下
实现一个完整的监控体系需要以下几个功能:
- 数据采集(xxx_export)
- 数据抓取(prometheus)
- 数据存储(prometheus/cortex)
- 规则检测并生成告警(prometheus/cotex.ruler)
- 告警处理(alertmanager)
- 告警通知(一般根据自身业务和管理体系实现)
Alertmanager实现了告警处理(聚合、抑制、屏蔽、路由)
基本流程如下:
1. Prometheus Server监控目标主机上暴露的http接口(这里假设接口A),通过上述Promethes配置的’scrape_interval’定义的时间间隔,定期采集目标主机上监控数据。
2. 当接口A不可用的时候,Server端会持续的尝试从接口中取数据,直到”scrape_timeout”时间后停止尝试。这时候把接口的状态变为“DOWN”。
3. Prometheus同时根据配置的”evaluation_interval”的时间间隔,定期(默认1min)的对Alert Rule进行评估;当到达评估周期的时候,发现接口A为DOWN,即UP=0为真,激活Alert,进入“PENDING”状态,并记录当前active的时间;
4. 当下一个alert rule的评估周期到来的时候,发现UP=0继续为真,然后判断警报Active的时间是否已经超出rule里的‘for’ 持续时间,如果未超出,则进入下一个评估周期;如果时间超出,则alert的状态变为“FIRING”;同时调用Alertmanager接口,发送相关报警数据。
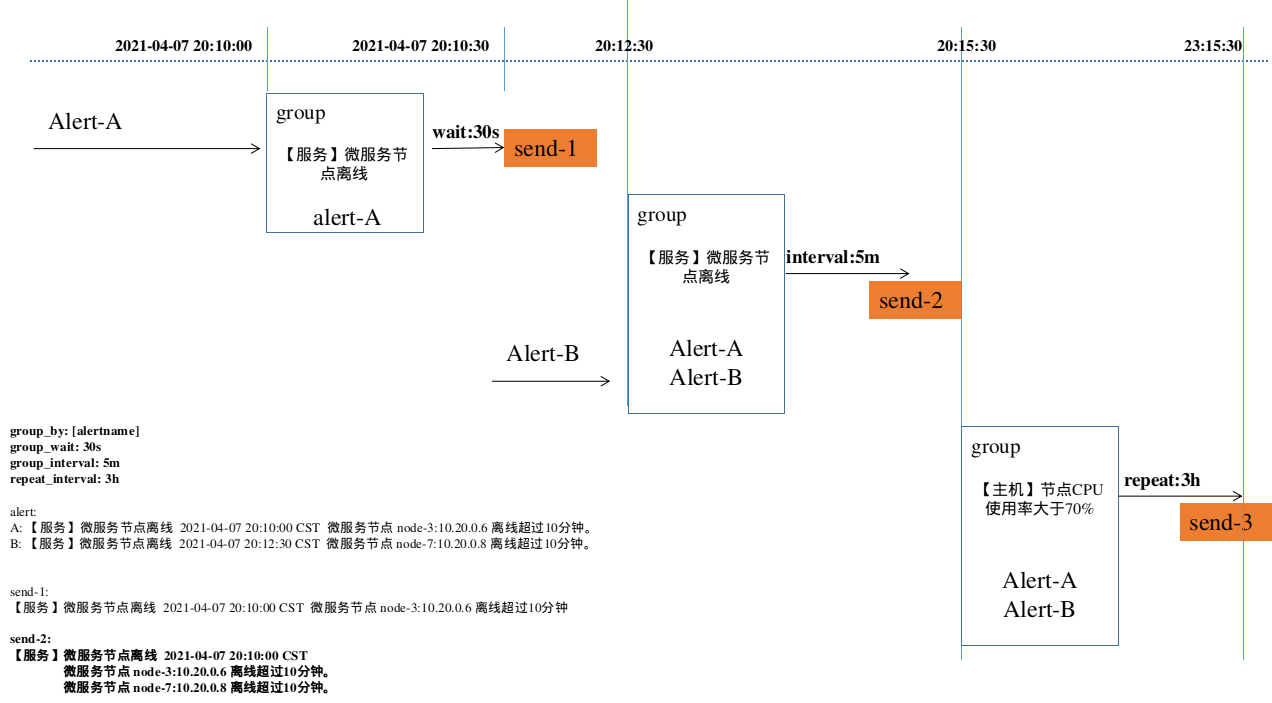
5. AlertManager收到报警数据后,会将警报信息进行分组,然后根据alertmanager配置的“group_wait”时间先进行等待。等wait时间过后再发送报警信息。
6. 属于同一个Alert Group的警报,在等待的过程中可能进入新的alert,如果之前的报警已经成功发出,那么间隔“group_interval”的时间间隔后再重新发送报警信息。比如配置的是邮件报警,那么同属一个group的报警信息会汇总在一个邮件里进行发送。
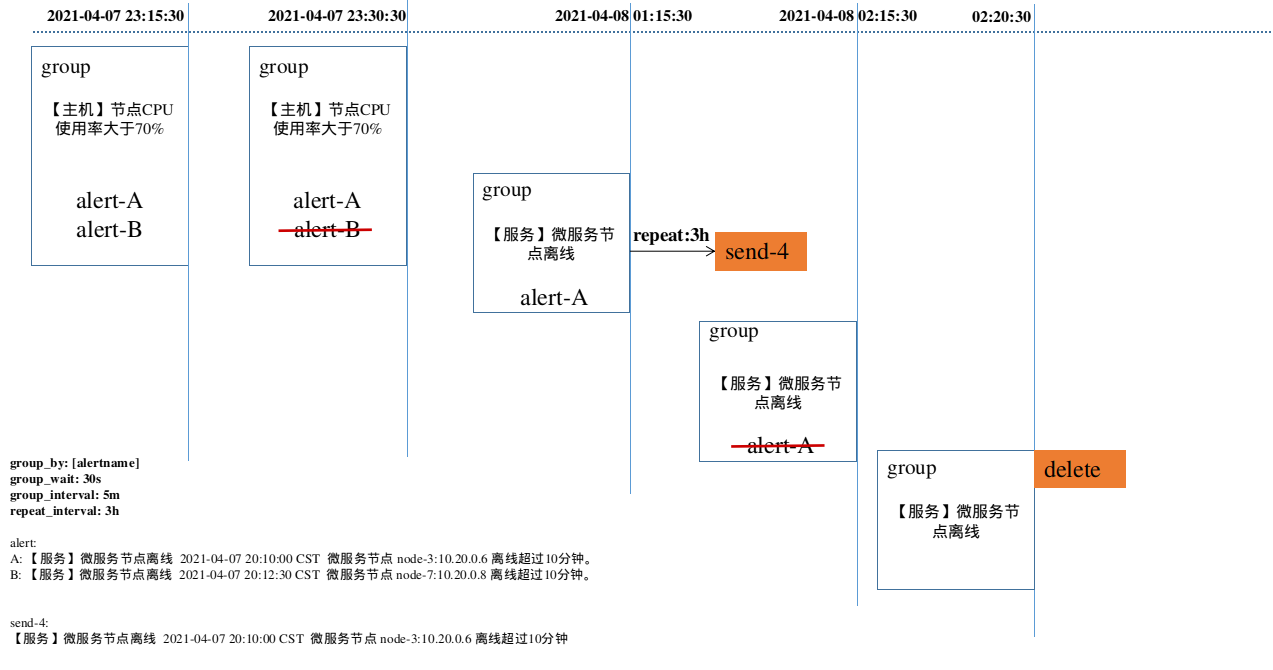
7. 如果Alert Group里的警报一直没发生变化并且已经成功发送,等待‘repeat_interval’时间间隔之后再重复发送相同的报警邮件;如果之前的警报没有成功发送,则相当于触发第6条条件,则需要等待group_interval时间间隔后重复发送。同时最后至于警报信息具体发给谁,满足什么样的条件下指定警报接收人,设置不同报警发送频率,这里有alertmanager的route路由规则进行配置。
告警发送通知流程-1:
告警发送通知流程-2:
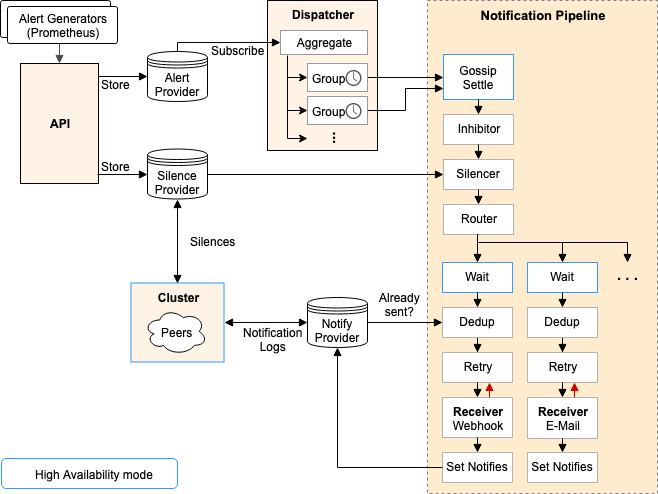
实现架构
配置文件
alertmanager
1 | global: |
参数说明
global
smtp_smarthost、smtp_from、smtp_auth_username、smtp_auth_password用于设置smtp邮件的地址及用户信息
hipchat_auth_token与安全性认证有关templates
指定告警信息展示的模版route
group_by:指定所指定的维度对告警进行分组
group_wait:指定每组告警发送等待的时间
group_interval:指定告警调度的时间间隔
repeat_interval:在连续告警触发的情况下,重复发送告警的时间间隔- receiver
指定告警默认的接受者 - routes
match_re:定义告警接收者的匹配方式
service:定义匹配的方式,纬度service值以foo1或foo2或baz开始/结束时表示匹配成功
receiver:定义了匹配成功的的情况下的接受者 - inhibit_rules
定义告警的抑制条件,过滤不必要的告警 - receivers
定义了具体的接收者,也就是告警具体的方式方式
prometheus
1 | # my global config |
参数说明:
- global下的scrape_interval
用于向pushgateway采集数据的频率,上图所示:每隔15秒向pushgateway采集一次指标数据 - global下的evaluation_interval
表示规则计算的频率,上图所示:每隔15秒根据所配置的规则集,进行规则计算 - global下的external_labels
为指标增加额外的维度,可用于区分不同的prometheus,在应用中多个prometheus可以对应一个alertmanager - rule_files
指定所配置规则文件,文件中每行可表示一个规则 - scrape_configs下的job_name
指定任务名称,在指标中会增加该维度,表示该指标所属的job - scrape_configs下的scrape_interval
覆盖global下的scrape_interval配置 - static_configs下的targets
指定指标数据源的地址,多个地址之间用逗号隔开
功能介绍
告警路由
路由字段即route的配置他控制了告警的聚合以及发送频率,route字段本身是一个树状的,每一个节点是一个配置,配置包括了接收人、match字段以及相应的告警发送配置例如:首次聚合时间、告警后续发送频率。对于到达的告警会收心进行match,如果有一个节点match并且该节点的continue字段为true,那么会继续递归遍历它的子节点,直到到达最后一个,这样就把匹配到同一个节点的告警经过group_by字段的分类,放置在不同的簇里面,这样就完成了告警的聚合功能。
这里有一点需要着重指出的一点是,对于每个簇,有三个字段影响了告警发送的频率,group_wait、group_interval、repeat_interval。
group_wait:当告警A第一次到达之后由于之前并没有告警簇,此时会进行创建,创建完之后会等待group_wait时间之后才会进行发送,这是为什么呢?这其实是为了解决告警风暴的问题,例如当服务集群a发生了告警,例如有10条,如果他们在group_wait这段时间内相继到达,那么最终他们就会被合并成一条告警进行发送。而不是收到10次告警信息。
group_interval:控制的是遍历告警簇的时间间隔,am当中当有新的告警到达时(之前没有进行过发生的告警)会进行告警簇的发送或者当检测到上次告警发送时间距离当前时间已经大于repeat_interval那么此时会进行发送。
路由配置格式
1 | #报警接收器 |
例子:
1 | # The root route with all parameters, which are inherited by the child |
告警聚合
告警聚合是非常重要的一个功能,好的聚合可以极大的减少告警风暴。
告警聚合在路由之后,每个路由节点可以配置自己的独特的聚合labels,比如按产品、集群、team等聚合。
例如上述示例,只按产品聚合,那么所有属于产品tcs的告警将与该告警一起聚合,所有属于产品tcs的告警都会放到一起,这种比较杂乱;如果按产品和类型聚合,那么属于不同机器的告警将分别聚合。
告警抑制
告警抑制是指高等级告警发生时,自动抑制低等级的告警发送,同时当高等级告警恢复是,放开对低等级的抑制,常见场景是磁盘满80%警告告警通知,90%发送严重告警通知。
告警抑制的实现也是基于labels,但是是基于全局的,不是特定路由,而且只支持静态label,这个地方的设计其实不太好,有两个问题:
- 全局容易出现不同用户的规则互相影响,为了减少此种行为的发生,我们应该为每个路由设定一个抑制规则,同时必须包含路由的labels
- 静态label对label规范化增加了不必要的限制,所有数据都必须拥有指定的抑制labels才能使用
告警屏蔽
告警屏蔽和告警抑制有点类似,但不一样,告警屏蔽是直接屏蔽报警,不再发送,不同报警之间无关联(告警抑制是高等级告警抑制低等级告警)。告警屏蔽也是基于labels,当告警中包含的labels满足(match)配置的屏蔽labels,就会发生屏蔽,不再发送告警。
原生的alertmanger屏蔽会直接在内存中屏蔽告警,无法记录到底哪些告警被屏蔽了,而且一旦屏蔽,及时报警恢复也不会发送通知,一旦设定,只能等屏蔽过期或者手工删除。
370对记录告警是个强需求,我们改造了alertmanager,让被屏蔽的告警也能继续发出来,但会加一个特殊的标记,这样我们就可以记录被屏蔽告警的信息,也可以捕获恢复。
抑制配置格式
1 | # Matchers that have to be fulfilled in the alerts to be muted. |
告警发送
告警发送是告警系统的最后一个处理点,也是众口难调的一个点,目前支持常见的第三方组件,但都不好用,且无法定制,一般都会基于webhook设计适合公司的发送能力。
通用配置格式
1 | # The unique name of the receiver. |
邮件接收器email_config
1 | # Whether or not to notify about resolved alerts. |
Slcack接收器slack_config
1 | # Whether or not to notify about resolved alerts. |
Webhook接收器webhook_config
1 | # Whether or not to notify about resolved alerts. |
Alertmanager会使用以下的格式向配置端点发送HTTP POST请求:
1 | { |
可以添加一个钉钉webhook,通过钉钉报警,由于POST数据需要有要求,简单实现一个数据转发脚本。
1 | from flask import Flask |
报警规则
报警规则允许你定义基于Prometheus表达式语言的报警条件,并发送报警通知到外部服务
报警规则通过以下格式定义:
1 | ALERT <alert name> |
可选的FOR语句,使得Prometheus在表达式输出的向量元素(例如高HTTP错误率的实例)之间等待一段时间,将警报计数作为触发此元素。如果元素是active,但是没有firing的,就处于pending状态。
LABELS(标签)语句允许指定一组标签附加警报上。将覆盖现有冲突的任何标签,标签值也可以被模板化。
ANNOTATIONS(注释)它们被用于存储更长的其他信息,例如警报描述或者链接,注释值也可以被模板化。
Templating(模板) 标签和注释值可以使用控制台模板进行模板化。$labels变量保存警报实例的标签键/值对,$value保存警报实例的评估值。
1 | # To insert a firing element's label values: |
报警规则示例:
1 | # Alert for any instance that is unreachable for >5 minutes. |
源码解析
alertmanager/cmd/alertmanager/main.go
服务启动
1 | // 程序入口main函数 |
上面的代码中大部分都有注释,基本都是一些初始化的操作,看下几个重要的点
1 | go disp.Run() // 告警聚合 |
1 | // alertmanager/api/v1/api.go |
下面我们每个模块单独分析,首先这里的api肯定是有服务调用才会运行,所以我们先不管这边,先看下初始化的时候,alertmanager都做了什么事情。
告警聚合初始化
1 | // go disp.Run() |
1 | func (d *Dispatcher) run(it provider.AlertIterator) { |
可以看到dispather起了一个run方法,调用Subscribe方法作为参数,在这里case alert, ok := <-it.Next()等待告警事件,先不急分析Subscribe方法,我们再看下告警抑制
告警抑制初始化
1 | // go inhibitor.Run() |
1 | // 运行抑制器,会开始订阅告警。然后开始循环,如果订阅的告警遍历器里面有告警, |
可以看到这里也是在case a := <-it.Next(),与聚合逻辑是一致的,都是调用的Subscribe方法
1 | // Alerts 接口负责装载告警对象,并且可以提供告警的遍历器,而且可以设置或可以通过告警 |
1 | // Subscribe 方法返回一个告警遍历器,里面包含全部活跃的告警(没有被解决或成功通知), |
可以看到这里维护了一份map,a.listeners[a.next] = listeningAlerts{alerts: ch, done: done},而上面的it.Next()是什么,其实就是ch。
1 | // NewAlertIterator 返回一个 AlertIterator 接口对象,底层实现类型是通过 alertIterator 来实现。 |
Inhibitor和Dispatcher在初始化时会调用Subscribe(),然后一直监听并接收新的alerts
到这里就初始化完成了,因为刚开始没有告警产生,所以两个逻辑都在case中阻塞,下面分析一下api的逻辑
API
1 | func (api *API) addAlerts(w http.ResponseWriter, r *http.Request) { |
看到60行的Put方法
1 | // Put 添加一到多个告警到告警集合里。并且通知到所有监听器里。 |
可以看到这里就是接收告警,然后将其塞到每个监听器,然后去通知每一个监听者去处理,即Inhibitor和Dispatcher会处理接收到的每个告警
下面看下处理流程
告警聚合处理流程
根据上面的分析,聚合初始化之后,最终调用的是processAlert方法
1 | // 处理告警,得到相应分组,并对相应的分组插入这个告警。 |
第35行是进行告警发送的流程,最终执行的是Exec方法
1 | // Stage 在所给予的上下文限制中处理所有告警。 |
1 | // createReceiverStage 为一个接口人创建一个扇出的阶段管道。这里循环这个接受方式的 |
在进行发送的时候依次进行,等待阶段、去重阶段、重试阶段、设置通知信息阶段,即分别是以下方法
1 | // NewWaitStage 返回一个新的等待阶段。设置wait方法到阶段之中。 |
WaitStage
等待间隔用来设置发送告警的等待时间,对于集群操作中,需要根据不同的peer设置不同的超时时间,如果仅仅一个Server本身,等待间隔设置为0;
1 | // clusterWait returns a function that inspects the current peer state and returns |
具体的实现上采用一个timer来传递信号,一旦时间到达后才返回对应的alerts,由于是串行执行的,所以消息传递会中止一段时间。
1 | // Exec implements the Stage interface. |
DedupStage
DedupStage用于管理告警的去重,传递的参数中包含了一个NotificationLog,用来保存告警的发送记录。当有多个机器组成集群的时候,NotificationLog会通过协议去进行通信,传递彼此的记录信息,加入集群中的A如果发送了告警,该记录会传递给B机器,并进行merge操作,这样B机器在发送告警的时候如果查询已经发送,则不再进行告警发送。关于NotificationLog的实现nflog可以查看nflog/nflog.go文件。
1 | // DedupStage filters alerts. |
具体的处理逻辑如下:
1 | func (n *DedupStage) Exec(ctx context.Context, l log.Logger, alerts ...*types.Alert) (context.Context, []*types.Alert, error) { |
其中的nflog.Query将根据接收和group key进行查询,一旦查找到,则不再返回对应的alerts. nflog设置了GC用来删除过期的日志记录。防止一直存在log中导致告警无法继续发送.
RetryStage
RetryStage利用backoff策略来管理告警的重发,对于没有发送成功的告警将不断重试,直到超时时间,numFailedNotifications用来传递发送失败的统计metrics,numNotifications用来发送成功的metrics统计信息。
1 | select { |
SetNotifiesStage
SetNotifiesStage用来设置发送告警的信息到nfLog,该模块仅仅用于被该AM发送的告警的记录(Retry组件传递的alerts和Dedup组件中发送出去的告警信息)。
1 | // Exec implements the Stage interface. |
告警抑制处理流程
1 | // 运行抑制器,会开始订阅告警。然后开始循环,如果订阅的告警遍历器里面有告警, |
链接:
https://just4fun.im/2018/05/25/study_alertmanager/

