我不知道萧红可有类似的体验,是否担心华美的袍上爬满虱子,也许她知道,但她不在乎,她更想要取暖,即使将虱子一道披挂上身。她像忍耐虱子一样,忍耐着世界的冷眼,还装成一派天真模样,仿佛因不谙世事而无从察觉,就可以不受伤害。
服务发现简介
云原生、容器场景下按需的资源使用方式对于监控系统而言就意味着没有了一个固定的监控目标,所有的监控对象(基础设施、应用、服
务)都在动态的变化,这对基于Push模式传统监控软件带来挑战。
对于Prometheus这一类基于Pull模式的监控系统,显然也无法继续使用的static_configs的方式静态的定义监控目标。而对于
Prometheus而言其解决方案就是引入一个中间的代理人(服务注册中心),这个代理人掌握着当前所有监控目标的访问信息,
Prometheus只需要向这个代理人询问有哪些监控目标控即可, 这种模式被称为服务发现。
通过服务发现的方式,管理员可以在不重启Prometheus服务的情况下动态的发现需要监控的Target实例信息。
Prometheus 每个被控目标暴露一个 endpoint 供 server 抓取,要获知这些 endpoint 有多种方式,最简单的是在配置文件里静态配置,
还有基于 k8s、consul、dns 等多种方式,基于文件的服务发现是比较灵活普遍的一种方式。
Prometheus采用pull方式拉取监控数据,需要实时感知被监控服务(Target)的变化.服务发现(serviceDiscover)支持多种服务发现系统,
这些系统可以动态感知被监控的服务(Target)的变化,把变化的被监控服务(Target)转换为targetgroup.Group的结构,通过管道up发送个
服务发现(serviceDiscover).以版本 v2.27为例,目前服务发现(serviceDiscover)支持的服务发现系统类型如下:
1 | // Package install has the side-effect of registering all builtin |
服务发现接口
服务发现(serviceDiscover)为了实现对以上服务发现系统的统一管理,提供了一个Discoverer接口,由各个服务发现系统来实现,然后把
上线的服务(Target)通过up管道发送给服务发现(serviceDiscover)
1 | prometheus/discovery/manager.go |
除了静态服务发现系统(StaticConfigs)在prometheus/discovery/manager.go中实现了以上接口,其他动态服务发现系统,在
prometheus/discovery/下都在有各自的目录下实现。
服务发现配置
示例配置文件:prometheus.yml
1 | # my global config |
配置文件初始化
1
2
3
4prometheus/cmd/prometheus/main.go
//discovery.Name("scrape")用于区分notify
discoveryManagerScrape = discovery.NewManager(ctxScrape, log.With(logger, "component", "discovery manager scrape"), discovery.Name("scrape"))调用NewManager方法,实例化Manager结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21prometheus/discovery/manager.go
// NewManager is the Discovery Manager constructor.
func NewManager(ctx context.Context, logger log.Logger, options ...func(*Manager)) *Manager {
if logger == nil {
logger = log.NewNopLogger()
}
mgr := &Manager{
logger: logger,
syncCh: make(chan map[string][]*targetgroup.Group),
targets: make(map[poolKey]map[string]*targetgroup.Group),
discoverCancel: []context.CancelFunc{},
ctx: ctx,
updatert: 5 * time.Second,
triggerSend: make(chan struct{}, 1),
}
for _, option := range options {
option(mgr)
}
return mgr
}结构体Manager定义如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29prometheus/discovery/manager.go
// Manager maintains a set of discovery providers and sends each update to a map channel.
// Targets are grouped by the target set name.
type Manager struct {
logger log.Logger //日志
name string // 用于区分srape和notify,因为他们用的同一个discovery/manager.go
mtx sync.RWMutex //同步读写锁
ctx context.Context //协同控制,比如系统退出
discoverCancel []context.CancelFunc // 处理服务下线
// Some Discoverers(eg. k8s) send only the updates for a given target group
// so we use map[tg.Source]*targetgroup.Group to know which group to update.
targets map[poolKey]map[string]*targetgroup.Group //发现的服务(Targets)
// providers keeps track of SD providers.
providers []*provider // providers的类型可分为kubernetes,DNS等
// The sync channel sends the updates as a map where the key is the job value from the scrape config.
// key 是 prometheus 配置文件的 job_name,value 是其对应的 targetgroup
// 把发现的服务Targets)通过管道形式通知给scrapeManager
syncCh chan map[string][]*targetgroup.Group
// How long to wait before sending updates to the channel. The variable
// should only be modified in unit tests.
updatert time.Duration
// The triggerSend channel signals to the manager that new updates have been received from providers.
// 这是一个用于通知 manager 有 provider 进行了更新的 channel
triggerSend chan struct{}
}比较重要的成员是 targets,它保存了全量的 target,poolKey 是一个结构体,由 job_name 和 provider_name 组成
1
2
3
4
5
6
7prometheus/discovery/manager.go
// poolKey定义了每个发现的服务的来源
type poolKey struct {
setName string //对应系统名/索引值,比如:string/0(静态服务发现),DNS/1(动态服务发现)
provider string //对应job_name
}通过 m.registerProviders 可以看到 setName 就是 “file”/“dns”/“consul”…,provider 是 provider 对象的 name 字段,是 “file”/“dns”/
“consul”… 后面跟上这个 m.provider 有多少个发现文件,比如 file_SD_discovrer 配置了3个yml文件,poolKey 的 provider 字段就
是 “file/3”
通过匿名函数加载prometheus.yml的scrape_configs下对应配置
1
2
3
4
5
6
7
8
9prometheus/cmd/prometheus/main.go
func(cfg *config.Config) error {
c := make(map[string]sd_config.ServiceDiscoveryConfig)
for _, v := range cfg.ScrapeConfigs {
c[v.JobName] = v.ServiceDiscoveryConfig
}
return discoveryManagerScrape.ApplyConfig(c)
},以示例配置文件prometheus.yml为例,包含两个jobs,job_name分别是prometheus和node,每个job可以包含多个targets.以job_name:node为例,匿名函数变量v输出如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29(dlv) p v
*github.com/prometheus/prometheus/config.ScrapeConfig {
JobName: "node",
HonorLabels: false,
Params: net/url.Values nil,
ScrapeInterval: 10000000000,
ScrapeTimeout: 10000000000,
MetricsPath: "/metrics",
Scheme: "http",
SampleLimit: 0,
ServiceDiscoveryConfig: github.com/prometheus/prometheus/discovery/config.ServiceDiscoveryConfig {
StaticConfigs: []*github.com/prometheus/prometheus/discovery/targetgroup.Group len: 1, cap: 1, [
*(*"github.com/prometheus/prometheus/discovery/targetgroup.Group")(0xc0018a27b0),
],
DNSSDConfigs: []*github.com/prometheus/prometheus/discovery/dns.SDConfig len: 0, cap: 0, nil,
FileSDConfigs: []*github.com/prometheus/prometheus/discovery/file.SDConfig len: 0, cap: 0, nil,
......
......
......
AzureSDConfigs: []*github.com/prometheus/prometheus/discovery/azure.SDConfig len: 0, cap: 0, nil,
TritonSDConfigs: []*github.com/prometheus/prometheus/discovery/triton.SDConfig len: 0, cap: 0, nil,},
HTTPClientConfig: github.com/prometheus/common/config.HTTPClientConfig {
BasicAuth: *github.com/prometheus/common/config.BasicAuth nil,
BearerToken: "",
BearerTokenFile: "",
ProxyURL: (*"github.com/prometheus/common/config.URL")(0xc000458cf8),
TLSConfig: (*"github.com/prometheus/common/config.TLSConfig")(0xc000458d00),},
RelabelConfigs: []*github.com/prometheus/prometheus/pkg/relabel.Config len: 0, cap: 0, nil,
MetricRelabelConfigs: []*github.com/prometheus/prometheus/pkg/relabel.Config len: 0, cap: 0, nil,}由以上结果可知,job_name:node对应静态服务发现系统(StaticConfigs).其实,在配置文件prometheus.yml中的两个job_names
都对应静态服务发现系统(StaticConfigs)
ApplyConfig方法实现逻辑比较清晰:先实现每个job的Discoverer接口,然后启动该job对应的服务发现系统
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27prometheus/discovery/manager.go
// ApplyConfig removes all running discovery providers and starts new ones using the provided config.
func (m *Manager) ApplyConfig(cfg map[string]sd_config.ServiceDiscoveryConfig) error {
m.mtx.Lock()
defer m.mtx.Unlock()
for pk := range m.targets {
if _, ok := cfg[pk.setName]; !ok {
discoveredTargets.DeleteLabelValues(m.name, pk.setName)
}
}
// 先把所有的Discoverer取消掉,这样做比较简单,毕竟配置文件修改频率非常低,没大毛病
// 实现方式就是我们上面提到的Manager.discoverCancel这个取消函数的数组,遍历调用就是了
m.cancelDiscoverers()
// name对应job_name,scfg是给出该job_name对应的服务发现系统类型,每个job_name下可以包含多种服务发现系统类型,但用的比较少
for name, scfg := range cfg {
m.registerProviders(scfg, name)
discoveredTargets.WithLabelValues(m.name, name).Set(0)
}
for _, prov := range m.providers {
//启动每个job下对应的服务发现系统
m.startProvider(m.ctx, prov)
}
return nil
}ApplyConfig方法主要通过调用方法:registerProviders()和startProvider()实现以上功能
registerProviders方法先判断每个job_name下包含所有的服务发现系统类型,接着由其对应的服务发现系统实现Discoverer接口,并构建provider和TargetGroups
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44// registerProviders returns a number of failed SD config.
func (m *Manager) registerProviders(cfgs Configs, setName string) int {
var (
failed int
added bool
)
add := func(cfg Config) {
for _, p := range m.providers {
if reflect.DeepEqual(cfg, p.config) {
p.subs = append(p.subs, setName)
added = true
return
}
}
typ := cfg.Name()
d, err := cfg.NewDiscoverer(DiscovererOptions{
Logger: log.With(m.logger, "discovery", typ),
})
if err != nil {
level.Error(m.logger).Log("msg", "Cannot create service discovery", "err", err, "type", typ)
failed++
return
}
m.providers = append(m.providers, &provider{
name: fmt.Sprintf("%s/%d", typ, len(m.providers)),
d: d,
config: cfg,
subs: []string{setName},
})
added = true
}
for _, cfg := range cfgs {
add(cfg)
}
if !added {
// Add an empty target group to force the refresh of the corresponding
// scrape pool and to notify the receiver that this target set has no
// current targets.
// It can happen because the combined set of SD configurations is empty
// or because we fail to instantiate all the SD configurations.
add(StaticConfig{{}})
}
return failed
}StaticConfigs对应TargetGroups, 以job_name:node为例,TargetGroups对应输出如下:
1
2
3
4
5
6
7
8
9
10
11
12
13(dlv) p setName
"node"
(dlv) p StaticConfigs
[]*github.com/prometheus/prometheus/discovery/targetgroup.Group len: 1, cap: 1, [
*{
Targets: []github.com/prometheus/common/model.LabelSet len: 1, cap: 1, [
[
"__address__": "localhost:9100",
],
],
Labels: github.com/prometheus/common/model.LabelSet nil,
Source: "0",},
]每个job_name对应一个TargetGroups,而每个TargetGroups可以包含多个provider,每个provider包含实现对应的Discoverer接口和job_name等.所以,对应关系:job_name -> TargetGroups -> 多个targets -> 多个provider -> 多个Discover.部分示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20(dlv) p m.providers
[]*github.com/prometheus/prometheus/discovery.provider len: 2, cap: 2, [
*{
name: "string/0",
d: github.com/prometheus/prometheus/discovery.Discoverer(*github.com/prometheus/prometheus/discovery.StaticProvider) ...,
subs: []string len: 1, cap: 1, [
"prometheus",
],
config: interface {}(string) *(*interface {})(0xc000536268),},
*{
name: "string/1",
d: github.com/prometheus/prometheus/discovery.Discoverer(*github.com/prometheus/prometheus/discovery.StaticProvider) ...,
subs: []string len: 1, cap: 1, ["node"],
config: interface {}(string) *(*interface {})(0xc000518b78),},
]
(dlv) p m.providers[0].d
github.com/prometheus/prometheus/discovery.Discoverer(*github.com/prometheus/prometheus/discovery.StaticProvider) *{
TargetGroups: []*github.com/prometheus/prometheus/discovery/targetgroup.Group len: 1, cap: 1, [
*(*"github.com/prometheus/prometheus/discovery/targetgroup.Group")(0xc000ce09f0),
],}startProvider方法逐一启动job_name对应的所有服务发现系统
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16prometheus/discovery/manager.go
func (m *Manager) startProvider(ctx context.Context, p *provider) {
level.Debug(m.logger).Log("msg", "Starting provider", "provider", p.name, "subs", fmt.Sprintf("%v", p.subs))
ctx, cancel := context.WithCancel(ctx)
updates := make(chan []*targetgroup.Group)
m.discoverCancel = append(m.discoverCancel, cancel)
// 第一个协程启动具体的发现的服务,作为[]*targetgroup.Group的生产者
go p.d.Run(ctx, updates)
// 第二个协程是[]*targetgroup.Group的消费者
go m.updater(ctx, p, updates)
}
// 备注:Run方法调用位置是实现Discoverer的服务发现系统中.若是静态服务发现,Run方法在prometheus/discovery/manager.go中实现,若是动态服务发现系统,则在对应系统的目录下实现.Run方法从结构体StaticProvider中取值,传递给[]*targetgroup.Group,作为服务发现的生产者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26prometheus/discovery/discovery.go
type Discoverer interface {
// Run hands a channel to the discovery provider (Consul, DNS, etc.) through which
// it can send updated target groups. It must return when the context is canceled.
// It should not close the update channel on returning.
Run(ctx context.Context, up chan<- []*targetgroup.Group)
}
prometheus/discovery/manager.go
// StaticProvider holds a list of target groups that never change.
type StaticProvider struct {
TargetGroups []*targetgroup.Group
}
// Run implements the Worker interface.
func (sd *StaticProvider) Run(ctx context.Context, ch chan<- []*targetgroup.Group) {
// We still have to consider that the consumer exits right away in which case
// the context will be canceled.
select {
case ch <- sd.TargetGroups:
case <-ctx.Done():
}
close(ch)
}updater方法从[]*targetgroup.Group获取TargetGroups,并把它发传给结构体Manager中对应的Targets,Manager中对应的Targets是map类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25prometheus/discovery/manager.go
func (m *Manager) updater(ctx context.Context, p *provider, updates chan []*targetgroup.Group) {
for {
select {
case <-ctx.Done(): //退出
return
case tgs, ok := <-updates: // 从[]*targetgroup.Group取TargetGroups
receivedUpdates.WithLabelValues(m.name).Inc()
if !ok {
level.Debug(m.logger).Log("msg", "discoverer channel closed", "provider", p.name)
return
}
// subs对应job_names,p.name对应系统名/索引值,比如:string/0
for _, s := range p.subs {
m.updateGroup(poolKey{setName: s, provider: p.name}, tgs)
}
select {
case m.triggerSend <- struct{}{}:
default:
}
}
}
}更新结构体Manager对应的targets,key是结构体poolKey,value是传递过来的TargetGroups,其中包含targets
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15prometheus/discovery/manager.go
func (m *Manager) updateGroup(poolKey poolKey, tgs []*targetgroup.Group) {
m.mtx.Lock()
defer m.mtx.Unlock()
for _, tg := range tgs {
if tg != nil { // Some Discoverers send nil target group so need to check for it to avoid panics.
if _, ok := m.targets[poolKey]; !ok {
m.targets[poolKey] = make(map[string]*targetgroup.Group)
}
m.targets[poolKey][tg.Source] = tg //一个tg对应一个job,在map类型targets中,结构体poolkey和tg.Source可以确定一个tg,即job
}
}
}
服务发现启动
在main.go方法中启一个协程,运行Run()方法
1 | prometheus/cmd/prometheus/main.go |
1 | // Run starts the background processing |
Run方法再起一个协程,运行sender()方法,sender方法的主要功能是处理结构体Manager中map类型的targets,然后传给结构
体Manager中的map类型syncCh:syncCh chan map[string][]*targetgroup.Group
sender 通过一个计时器达到限制更新速率的目的,因为有些 discoverer 可能会过于频繁的更新 target。每次 Run() 都会根据 context 执
行取消发现的操作。周期计时器用法值得学,注意创建以后要延迟关闭。
每5秒检查一次 m.triggerSend 中有没有更新的信号,如果有更新的信号,就组装 map[string][]*targetgroup.Group 发送到
m.SyncCh 中,由于 m.SyncCh 是无缓冲通道,如果没能接收的话,就等到下次检查到更新信号再重试发送,这里的嵌套 select case 非
常值得学习
1 | func (m *Manager) sender() { |
负责转换的allGroups()方法,m.allGroups 方法读取自身的 targets 成员变量中的值组装成 map 返回给调用者,用于向自身的 syncCh 发送这个 map,最终通知给 scraper;
当 SD 发现删除了某个 target group 时会发送一个空的 target group,此处对这个动作的意义做了说明,空的 target group 会通知
scraper 停止再抓取这些 target
1 | func (m *Manager) allGroups() map[string][]*targetgroup.Group { |
服务发现和指标采集通信
服务发现 (serviceDiscover)和指标采集 (scrapeManager)通信,负责指标采集的服务监听的正是结构体Manager中的syncCh,由此实现了两个服务的通信
1 | prometheus/cmd/prometheus/main.go |
小结
至此,服务发现的主要功能就梳理出来了
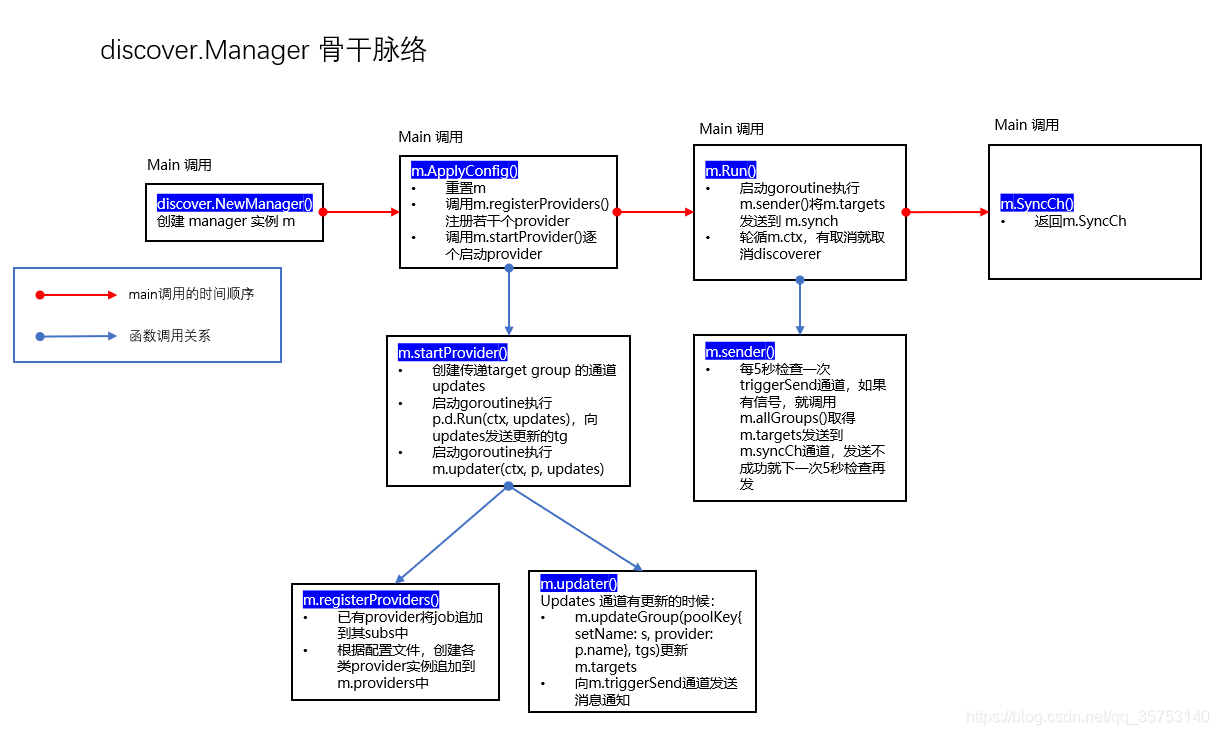
主程序调用 NewManager() Manager 实例
主程序调用 m.ApplyConfig() 根据配置文件配置并启动 Manager 实例,Manager 实例包括一组 Provider,其持有具体的 Discoverer,Discoverer 在运行时定期刷新target group,通过 channel 发送给 Manager 将其保存在 m.targets 中,并向 m.triggerSend channel 发送通知信号
m.Run() 按照 m.updatert 设定的时间间隔检查有没有更新的信号,有的话就把自己的 targets 字段中的 targets 发送给自身的 m.syncCh channel
主程序调用 m.SyncCh() 方法获取 channel 并从中取得 target
参考:

