生活像一只蝴蝶,没有破茧的勇气,哪来飞舞的美丽。生活像一只蜜蜂,没有勤劳和努力,怎能尝到花粉的甜蜜,越努力越幸运!
scrape模块在prometheus中负责着采集具体指标,并记录到后端存储中的功能,可以说是prometheus最为核心的一个功能模块
篇幅较长,需要耐心
指标采集简介
为了从服务发现(serviceDiscover)实时获取监控服务(targets),指标采集(scrapeManager)通过协程把管道(chan)获取来的服务(targets)存
进一个map类型:map[string][]*targetgroup.Group.其中,map的key是job_name,map的value是结构体targetgroup.Group,
该结构体包含该job_name对应的Targets,Labes和Source
指标采集(scrapeManager)获取服务(targets)的变动,可分为多种情况,以服务增加为例,若有新的job添加,指标采集(scrapeManager)
会进行重载,为新的job创建一个scrapePool,并为job中的每个target创建一个scrapeLoop.若job没有变动,只增加了job下对应的
targets,则只需创建新的targets对应的scrapeLoop
指标采集流程
总体流程
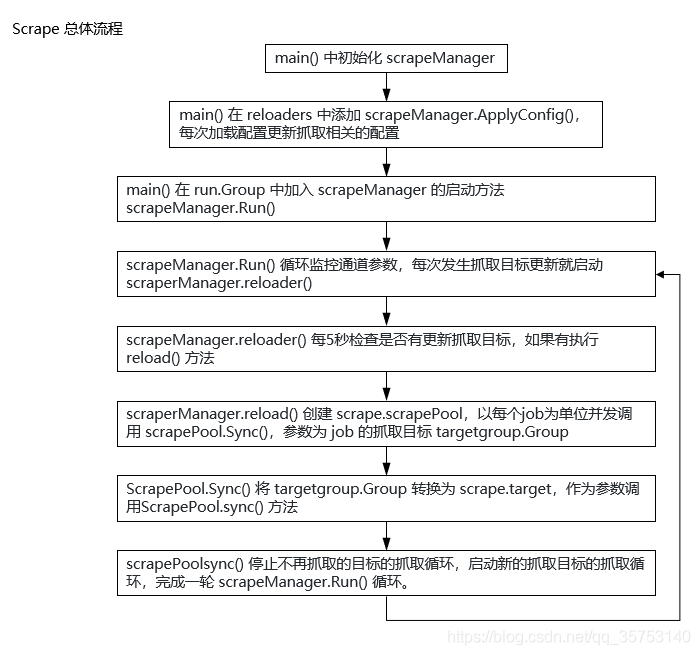
静态结构
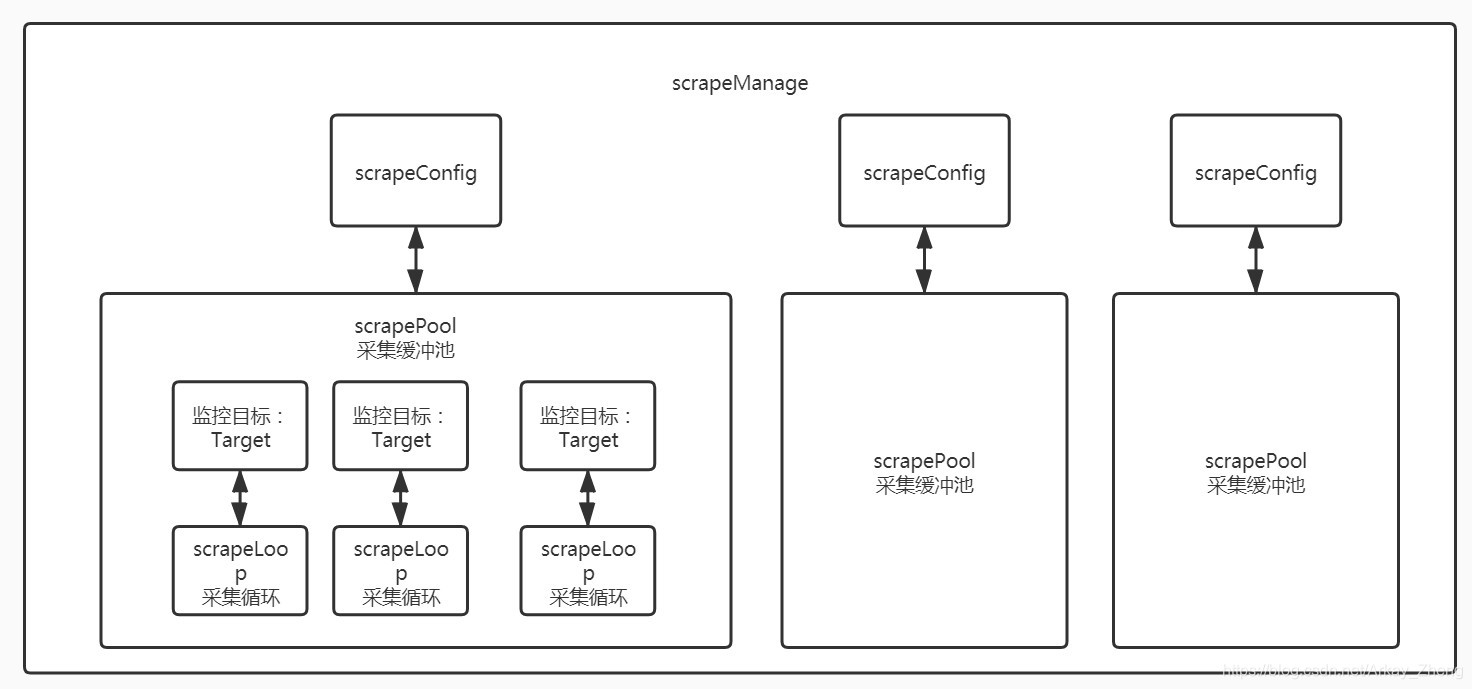
在一个管理面(scrapeManager)中,每次初始化(重载),会根据配置的份数创建出对应的采集缓冲池(scrapePool);在缓冲池
中,每一个监控目标会对应创建一个采集循环(scrapeLoop);采集循环可以认为是最小的一个工作单位,下图进一步解析采集循环的
静态结构
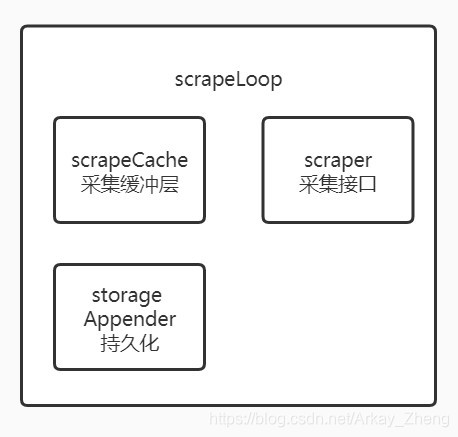
采集的主要流程函数在scrape.go中的scrapeAndReport,采集接口(scraper)采集到数据后,会先调用append方法写到采集缓冲层
(scrapeCache)中,最后调用持久化的Commit方法写到后端存储
指标采集配置
指标采集(scrapeManager)调用scrapeManager.ApplyConfig方法,完成配置初始化及应用
1 | prometheus/scrape/manager.go |
调用reload方法重新加载配置文件
1 | prometheus/scrape/scrape.go |
每次 reload 配置文件的时候都会重新加载 scrape 的配置,config/config.go 中的 ScrapeConfig 结构体
1 | // ScrapeConfig configures a scraping unit for Prometheus. |
指标采集启动
- main 函数中初始化 scrapeManager 实例
1 | prometheus/cmd/prometheus/main.go |
fanoutStorage 是读写多个底层存储的代理,实现了 storage.Appendable 接口
NewManager方法了实例化结构体Manager
1 | prometheus/scrape/manager.go |
结构体Manager维护map类型的scrapePools和targetSets,两者key都是job_name,但scrapePools的value对应结构体scrapepool,而
targetSets的value对应的结构体是Group,分别给出了两者的示例输出
1 | prometheus/scrape/manager.go |
- 指标采集(scrapeManager)获取实时监控服务(targets)的入口函数
scrapeManager.Run(discoveryManagerScrape.SyncCh())
1 | prometheus/cmd/prometheus/main.go |
这里会起一个协程运行Run方法,从服务发现(serviceDiscover)实时获取被监控服务(targets)
1 | prometheus/scrape/manager.go |
以上流程还是比较清晰,若服务发现(serviceDiscovery)有服务(target)变动,Run方法就会向管道triggerReload注入值:
m.triggerReload <- struct{}{}中,并起了一个协程,运行reloader方法.用于定时更新服务(targets).启动这个协程应该是为了防止阻塞
从服务发现(serviceDiscover)获取变动的服务(targets)
reloader方法启动了一个定时器,在无限循环中每5s判断一下管道triggerReload,若有值,则执行reload方法
1 | prometheus/scrape/manager.go |
reload方法会根据job_name比较targetSets,scrapePools和scrapeConfigs的一致性,并把每个job_name下的类型为
[]*targetgroup.Group的groups通过协程传给sp.Sync方法,增加并发
1 | prometheus/scrape/manager.go |
sp.Sync方法引入了Target结构体,把[]*targetgroup.Group类型的groups转换为targets类型,其中每个groups对应一个job_name下多
个targets.随后,调用sp.sync方法,同步scrape服务
1 | // Sync converts target groups into actual scrape targets and synchronizes |
scrape.Target 是一次抓取的具体对象,包含了抓取和抓取后存储所需要的全部信息。从 targetGroup.Group 到 scrape.Target 的转换过程如下:
targetsFromGroup函数遍历每个targetGroup.Group中的Target,合并targetGroup.Group的公共标签集(记为A)和这个Target本身的标签集(记为B)为标签集C。
populateLabels函数从C和*config.ScrapeConfig中创建Target。
Target结构体以及方法定义
1 | // TargetHealth describes the health state of a target. |
sp.sync方法对比新的Target列表和原来的Target列表,若发现不在原来的Target列表中,则新建该targets的scrapeLoop,通过协程启动
scrapeLoop的run方法,并发采集存储指标.然后判断原来的Target列表是否存在失效的Target,若存在,则移除
1 | // sync takes a list of potentially duplicated targets, deduplicates them, starts |
sp.sync方法起了一个协程运行scrapePool的run方法去采集并存储监控指标(metrics)
1 | func (sl *scrapeLoop) run(interval, timeout time.Duration, errc chan<- error) { |
run方法主要实现两个功能:指标采集(scrape)和指标存储.此外,为了实现对象的复用,在采集(scrape)过程中,使用了sync.Pool机制
提高性能,即每次采集(scrape)完成后,都会申请和本次采集(scrape)指标存储空间一样的大小的bytes,加入到buffer中,以备下次指标
采集(scrape)直接使用
最后看一下scrape函数的代码,这个函数其实就是发送http get请求,并把响应结果写入到io.Writer中
1 | func (s *targetScraper) scrape(ctx context.Context, w io.Writer) (string, error) { |
至此就完成了指标采集
参考:

