人生不过如此,且行且珍惜,每一次的失败,都是成功的伏笔;每一次的考验,都有一份收获;每一次的泪水,都有一次醒悟;每一次的磨难,都有生命的财富。
高可用简介
之前我们主要讨论了Prometheus Server自身的高可用问题。而接下来,重点将放在告警处理也就是Alertmanager部分。如下所示。
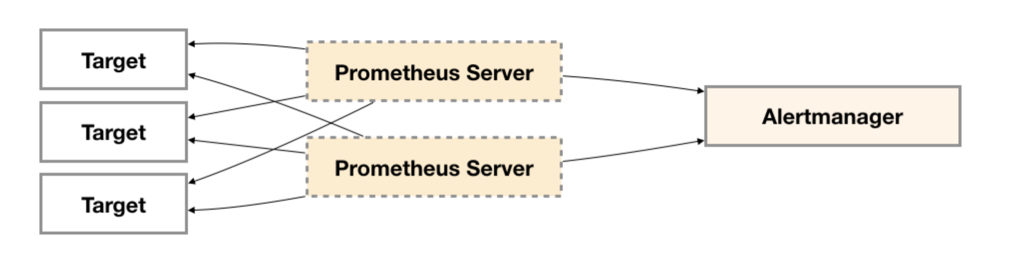
为了提升Promthues的服务可用性,通常用户会部署两个或者两个以上的Promthus Server,它们具有完全相同的配置包括Job配置,以及告警配置等。当某一个Prometheus Server发生故障后可以确保Promthues持续可用。
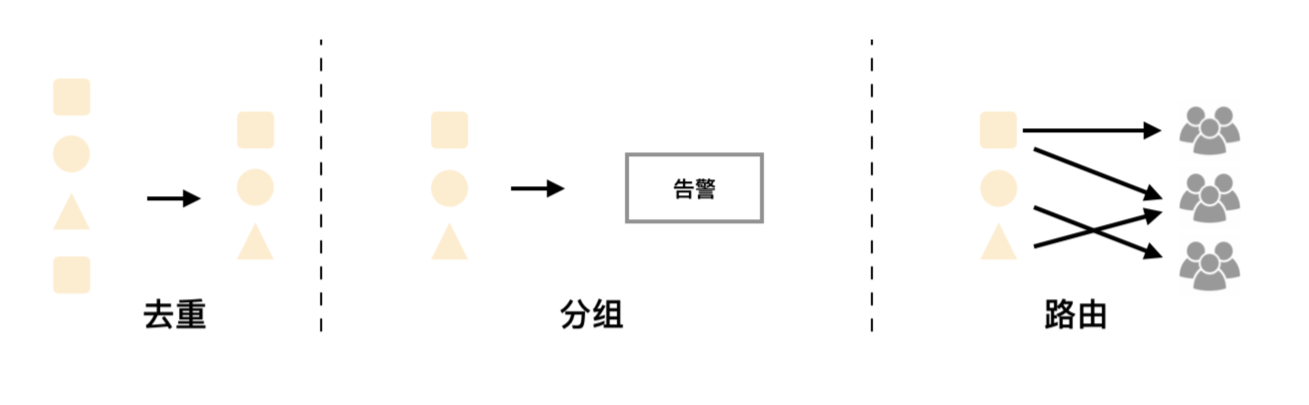
同时基于Alertmanager的告警分组机制即使不同的Prometheus Sever分别发送相同的告警给Alertmanager,Alertmanager也可以自动将这些告警合并为一个通知向receiver发送。
但不幸的是,虽然Alertmanager能够同时处理多个相同的Prometheus Server所产生的告警。但是由于单个Alertmanager的存在,当前的部署结构存在明显的单点故障风险,当Alertmanager单点失效后,告警的后续所有业务全部失效。
如下所示,最直接的方式,就是尝试部署多套Alertmanager。但是由于Alertmanager之间不存在并不了解彼此的存在,因此则会出现告警通知被不同的Alertmanager重复发送多次的问题。
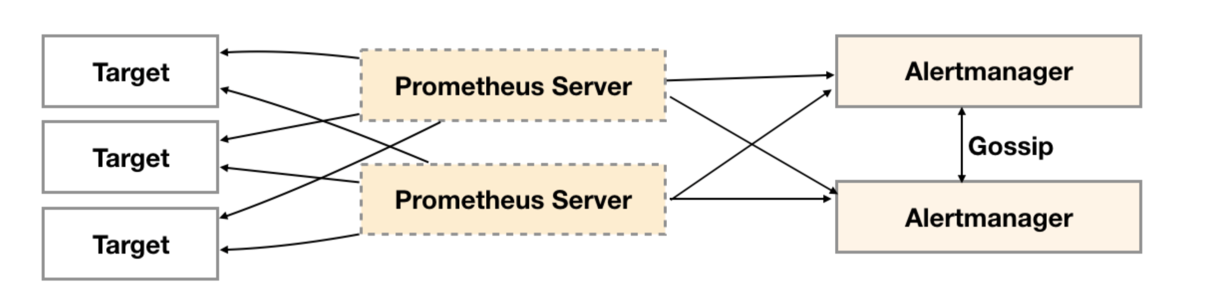
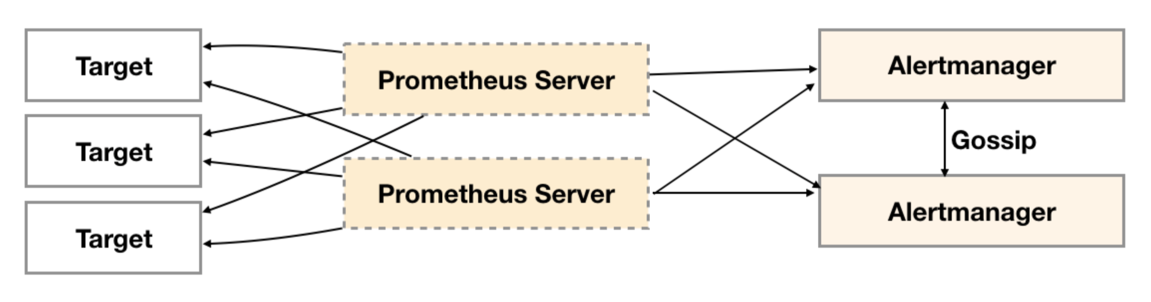
为了解决这一问题,如下所示。Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
Gossip协议
Gossip protocol 也叫 Epidemic Protocol (流行病协议),实际上它还有很多别名,比如:“流言算法”、“疫情传播算法”等。
这个协议的作用就像其名字表示的意思一样,非常容易理解,它的方式其实在我们日常生活中也很常见,比如电脑病毒的传播,森林大火,细胞扩散等等。
这里先简单介绍一下 Gossip 协议的执行过程:
Gossip 过程是由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
Gossip 演示
现在,我们通过一个具体的实例来深入体会一下 Gossip 传播的完整过程
为了表述清楚,我们先做一些前提设定
1、Gossip 是周期性的散播消息,把周期限定为 1 秒
2、被感染节点随机选择 k 个邻接节点(fan-out)散播消息,这里把 fan-out 设置为 3,每次最多往 3 个节点散播。
3、每次散播消息都选择尚未发送过的节点进行散播
4、收到消息的节点不再往发送节点散播,比如 A -> B,那么 B 进行散播的时候,不再发给 A。
注意:Gossip 过程是异步的,也就是说发消息的节点不会关注对方是否收到,即不等待响应;不管对方有没有收到,它都会每隔 1 秒向周围节点发消息。异步是它的优点,而消息冗余则是它的缺点。
这里一共有 16 个节点,节点 1 为初始被感染节点,通过 Gossip 过程,最终所有节点都被感染:
Gossip 的特点(优势)
1)扩展性
网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。
2)容错
网络中任何节点的宕机和重启都不会影响 Gossip 消息的传播,Gossip 协议具有天然的分布式系统容错特性。
3)去中心化
Gossip 协议不要求任何中心节点,所有节点都可以是对等的,任何一个节点无需知道整个网络状况,只要网络是连通的,任意一个节点就可以把消息散播到全网。
4)一致性收敛
Gossip 协议中的消息会以一传十、十传百一样的指数级速度在网络中快速传播,因此系统状态的不一致可以在很快的时间内收敛到一致。消息传播速度达到了 logN。
5)简单
Gossip 协议的过程极其简单,实现起来几乎没有太多复杂性。
Gossip 的缺陷
分布式网络中,没有一种完美的解决方案,Gossip 协议跟其他协议一样,也有一些不可避免的缺陷,主要是两个:
1)消息的延迟
由于 Gossip 协议中,节点只会随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网的,因此使用 Gossip 协议会造成不可避免的消息延迟。不适合用在对实时性要求较高的场景下。
2)消息冗余
Gossip 协议规定,节点会定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤,因此就不可避免的存在消息重复发送给同一节点的情况,造成了消息的冗余,同时也增加了收到消息的节点的处理压力。而且,由于是定期发送,因此,即使收到了消息的节点还会反复收到重复消息,加重了消息的冗余。
Gossip 类型
Gossip 有两种类型:
- Anti-Entropy(反熵):以固定的概率传播所有的数据
- Rumor-Mongering(谣言传播):仅传播新到达的数据
Anti-Entropy 是 SI model,节点只有两种状态,Suspective 和 Infective,叫做 simple epidemics。
Rumor-Mongering 是 SIR model,节点有三种状态,Suspective,Infective 和 Removed,叫做 complex epidemics。
其实,Anti-entropy 反熵是一个很奇怪的名词,之所以定义成这样,Jelasity 进行了解释,因为 entropy 是指混乱程度(disorder),而在这种模式下可以消除不同节点中数据的 disorder,因此 Anti-entropy 就是 anti-disorder。换句话说,它可以提高系统中节点之间的 similarity。
在 SI model 下,一个节点会把所有的数据都跟其他节点共享,以便消除节点之间数据的任何不一致,它可以保证最终、完全的一致。
由于在 SI model 下消息会不断反复的交换,因此消息数量是非常庞大的,无限制的(unbounded),这对一个系统来说是一个巨大的开销。
但是在 Rumor Mongering(SIR Model) 模型下,消息可以发送得更频繁,因为消息只包含最新 update,体积更小。而且,一个 Rumor 消息在某个时间点之后会被标记为 removed,并且不再被传播,因此,SIR model 下,系统有一定的概率会不一致。
而由于,SIR Model 下某个时间点之后消息不再传播,因此消息是有限的,系统开销小。
Gossip 中的通信模式
在 Gossip 协议下,网络中两个节点之间有三种通信方式:
- Push: 节点 A 将数据 (key,value,version) 及对应的版本号推送给 B 节点,B 节点更新 A 中比自己新的数据
- Pull:A 仅将数据 key, version 推送给 B,B 将本地比 A 新的数据(Key, value, version)推送给 A,A 更新本地
- Push/Pull:与 Pull 类似,只是多了一步,A 再将本地比 B 新的数据推送给 B,B 则更新本地
如果把两个节点数据同步一次定义为一个周期,则在一个周期内,Push 需通信 1 次,Pull 需 2 次,Push/Pull 则需 3 次。虽然消息数增加了,但从效果上来讲,Push/Pull 最好,理论上一个周期内可以使两个节点完全一致。直观上,Push/Pull 的收敛速度也是最快的。
复杂度分析
对于一个节点数为 N 的网络来说,假设每个 Gossip 周期,新感染的节点都能再感染至少一个新节点,那么 Gossip 协议退化成一个二叉树查找,经过 LogN 个周期之后,感染全网,时间开销是 O(LogN)。由于每个周期,每个节点都会至少发出一次消息,因此,消息复杂度(消息数量 = N * N)是 O(N^2) 。注意,这是 Gossip 理论上最优的收敛速度,但是在实际情况中,最优的收敛速度是很难达到的。
假设某个节点在第 i 个周期被感染的概率为 pi,第 i+1 个周期被感染的概率为 pi+1 ,
1)则 Pull 的方式:
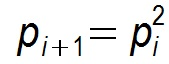
2)Push 方式:
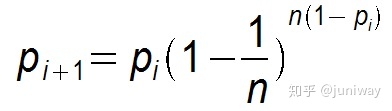
显然 Pull 的收敛速度大于 Push ,而每个节点在每个周期被感染的概率都是固定的 p (0<p<1),因此 Gossip 算法是基于 p 的平方收敛,也称为概率收敛,这在众多的一致性算法中是非常独特的。
高可用方案
上面我们详细介绍了goosip协议的实现,简单的说,Gossip有两种实现方式分别为Push-based和Pull-based。在Push-based当集群中某一节点A完成一个工作后,随机的从其它节点B并向其发送相应的消息,节点B接收到消息后在重复完成相同的工作,直到传播到集群中的所有节点。而Pull-based的实现中节点A会随机的向节点B发起询问是否有新的状态需要同步,如果有则返回。
在简单了解了Gossip协议之后,我们来看Alertmanager是如何基于Gossip协议实现集群高可用的。如下所示,当Alertmanager接收到来自Prometheus的告警消息后,会按照以下流程对告警进行处理:

- 在第一个阶段Silence中,Alertmanager会判断当前通知是否匹配到任何的静默规则,如果没有则进入下一个阶段,否则则中断流水线不发送通知;
- 在第二个阶段Wait中,Alertmanager会根据当前Alertmanager在集群中所在的顺序(index)等待index * 5s的时间;
- 当前Alertmanager等待阶段结束后,Dedup阶段则会判断当前Alertmanager数据库中该通知是否已经发送,如果已经发送则中断流水线,不发送告警,否则则进入下一阶段Send对外发送告警通知;
- 告警发送完成后该Alertmanager进入最后一个阶段Gossip,Gossip会通知其他Alertmanager实例当前告警已经发送。其他实例接收到Gossip消息后,则会在自己的数据库中保存该通知已发送的记录。
因此如下所示,Gossip机制的关键在于两点:
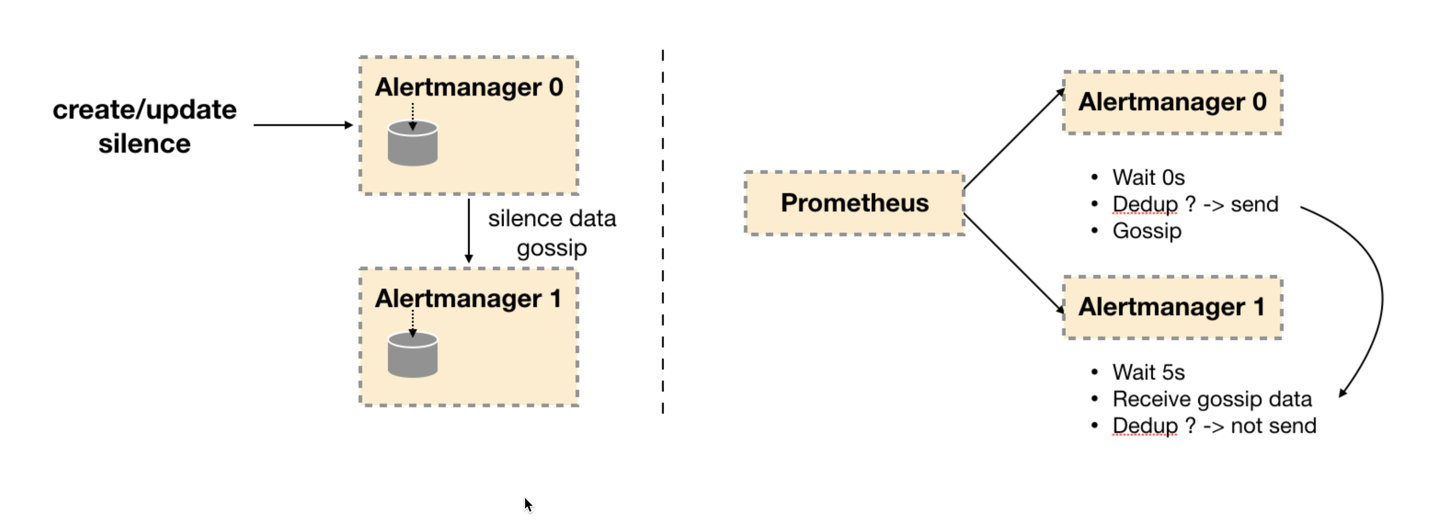
- Silence设置同步:Alertmanager启动阶段基于Pull-based从集群其它节点同步Silence状态,当有新的Silence产生时使用Push-based方式在集群中传播Gossip信息;
- 通知发送状态同步:告警通知发送完成后,基于Push-based同步告警发送状态。Wait阶段可以确保集群状态一致。
Alertmanager基于Gossip实现的集群机制虽然不能保证所有实例上的数据时刻保持一致,但是实现了CAP理论中的AP系统,即可用性和分区容错性。同时对于Prometheus Server而言保持了配置了简单性,Promthues Server之间不需要任何的状态同步。
高可用源码分析
集群启动
下面是从main.go中摘录的一些关于alertmanager组件集群的代码流程:
1 | // 代码来自alertmanager/cmd/alertmanager/main.go |
在cluster.Create中主要就是一些初始化集群的工作,里面比较重要的就是用到了ml, err := memberlist.Create(cfg),这里用到了一个基于Gossip协议来传播消息,用来管理分布式集群内节点发现、 节点失效探测、节点列表的软件包memberlist,关于这个包,有必要分析一下,没兴趣的可以跳过这一节:
memberlist
memberlist 是HashiCorp公司出品的go语言开发库,使用基于Gossip协议管理集群成员和成员失败检测。咱们本文的主题就是memberlist。严格说起来,memberlist是基于Gossip协议变种实现的,它的指导论文是康奈尔大学计算机科学系Abhinandan Das, Indranil Gupta, Ashish Motivala在2002年发表的《SWIM:Scalable Weakly-consistent/Infection-styleProcess Group Membership Protocol》。
Membership协议中文名是 可伸缩最终一致性感染成员组协议。原理通过一个有效的点对点随机探测机制进行监控协议成员的故障检测、更新传播。Memberlist 构建在SWIM Membership之上,跟原始gossip协议有了一些补充和调整。咱们接下去从项目介绍、节点状态、消息类型、数据通讯来解说下。
项目结构如下:
1 | total 536 |
项目基本流程如下:
项目在memberlist.go 函数Create启动,调用sate.go中函数schedule
Schedule函数开启probe协程、pushpull协程、gossip协程
probe协程:进行节点状态维护
push/pull协程:进行节点状态、用户数据同步
gossip协程:进行udp广播发送消息。
Memberlist 结构体
在结构体Memberlist中,成员变量也是按照功能不同分隔
1 | // 代码来自 github.com/hashicorp/memberlist/memberlist.go |
Config 结构体
1 | type Config struct { |
从create开始
1 | // 代码来自github.com/hashicorp/memberlist/memberlist.go |
这里面有两个重要步骤:
- newMemberlist
- m.schedule
newMemberlist
1 | // 代码来自github.com/hashicorp/memberlist/memberlist.go |
在newMemberlist中,最主要的动作就是开启了tcp服务(m.streamListen())和udp服务(m.packetListen()),那么就看看net服务(tcp和udp):
TCP 处理
1 | // 代码来自github.com/hashicorp/memberlist/net.go |
继续看下处理函数 m.handleConn(conn)
1 | // 代码来自github.com/hashicorp/memberlist/net.go |
整体来看,这个方法就是读取TCP流数据,然后对数据进行判断类型,进行相应的处理,ping包和user包暂时不看,看下pullPush的类型的处理,分为三步:
1 | // 代码来自github.com/hashicorp/memberlist/net.go |
可以看到tcp服务提供的功能就是:同步节点状态。
分别砍下这三个步骤的处理
readRemoteState
读取节点状态信息,并返回
1 | // 代码来自github.com/hashicorp/memberlist/net.go |
sendLocalState
发送本地存储的节点状态信息
1 | // 代码来自github.com/hashicorp/memberlist/net.go |
mergeRemoteState
更新节点状态
1 | // 代码来自github.com/hashicorp/memberlist/net.go |
1 | // 代码来自github.com/hashicorp/memberlist/state.go |
存在四种状态处理:
- StateAlive
- StateLeft
- StateDead/StateSuspect
这几种状态的处理在后面说
到这里小结一下,tcp链接,主要处理节点状态信息的同步与更新。
UDP 处理
1 | // 代码来自github.com/hashicorp/memberlist/net.go |
handleCommand
1 | func (m *Memberlist) handleCommand(buf []byte, from net.Addr, timestamp time.Time) { |
compoundMsg:处理函数为handleCompound,多个消息聚合在一起,进行分割,然后再重新调用handleCommand.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20func (m *Memberlist) handleCompound(buf []byte, from net.Addr, timestamp time.Time) {
// Decode the parts
// 消息分割
trunc, parts, err := decodeCompoundMessage(buf)
if err != nil {
m.logger.Printf("[ERR] memberlist: Failed to decode compound request: %s %s", err, LogAddress(from))
return
}
// Log any truncation
if trunc > 0 {
m.logger.Printf("[WARN] memberlist: Compound request had %d truncated messages %s", trunc, LogAddress(from))
}
// Handle each message
for _, part := range parts {
// 分割的消息重新调用handleCommand
m.handleCommand(part, from, timestamp)
}
}pingMsg:处理函数为:handlePing;
indirectPingMsg: 处理函数为handleindirectPing;
ackRespMsg: 处理函数为handleAck
suspectMsg/aliveMsg/deadMsg/userMsg: 处理函数为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// Determine the message queue, prioritize alive
queue := m.lowPriorityMsgQueue
if msgType == aliveMsg {
queue = m.highPriorityMsgQueue
}
// Check for overflow and append if not full
m.msgQueueLock.Lock()
if queue.Len() >= m.config.HandoffQueueDepth {
m.logger.Printf("[WARN] memberlist: handler queue full, dropping message (%d) %s", msgType, LogAddress(from))
} else {
queue.PushBack(msgHandoff{msgType, buf, from})
}
m.msgQueueLock.Unlock()
// Notify of pending message
select {
case m.handoffCh <- struct{}{}:
default:
}
default:
m.logger.Printf("[ERR] memberlist: msg type (%d) not supported %s", msgType, LogAddress(from))m.handoffCh <- struct{}{},是否还记得上面开启TCP和UDP的时候,还有一个协程运行着:
1
2
3go m.streamListen()
go m.packetListen()
go m.packetHandler()go m.packetHandler()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// packetHandler is a long running goroutine that processes messages received
// over the packet interface, but is decoupled from the listener to avoid
// blocking the listener which may cause ping/ack messages to be delayed.
func (m *Memberlist) packetHandler() {
for {
select {
case <-m.handoffCh:
for {
msg, ok := m.getNextMessage()
if !ok {
break
}
msgType := msg.msgType
buf := msg.buf
from := msg.from
switch msgType {
case suspectMsg:
m.handleSuspect(buf, from)
case aliveMsg:
m.handleAlive(buf, from)
case deadMsg:
m.handleDead(buf, from)
case userMsg:
m.handleUser(buf, from)
default:
m.logger.Printf("[ERR] memberlist: Message type (%d) not supported %s (packet handler)", msgType, LogAddress(from))
}
}
case <-m.shutdownCh:
return
}
}
}这里监听 m.handoffCh,当UDP有消息传过来时,分别处理以下类型的消息,就不展开了
suspectMsg
aliveMsg
deadMsg
userMsg
udp服务提供了一些基本的Command操作
schedule
- Schedule函数开启probe协程、pushpull协程、gossip协程
- probe协程:进行节点状态维护
- push/pull协程:进行节点状态、用户数据同步
- gossip协程:进行udp广播发送消息。
1 | // Schedule is used to ensure the Tick is performed periodically. This |
在这里面一共开启了三个定时任务,probe、pushpull、gossip
probe
当节点启动后,每隔一定时间间隔,会选取一个节点对其发送PING消息,当PING消息失败后,会随机选取 IndirectChecks 个节点发起间接PING的请求和直接更其再发起一个tcp PING消息。 收到间接PING请求的节点会根据请求中的地址发起一个PING消息,将PING的结果返回给间接请求的源节点。 如果探测超时之间内,本节点没有收到任何一个要探测节点的ACK消息,则标记要探测的节点状态为suspect。
1 | // Tick is used to perform a single round of failure detection and gossip |
1 | // probeNode handles a single round of failure checking on a node. |
pushpull
每隔一个时间间隔,随机选取一个节点,跟它建立tcp连接,然后将本地的全部节点 状态、用户数据发送过去,然后对端将其掌握的全部节点状态、用户数据发送回来,然后完成2份数据的合并。 此动作可以加速集群内信息的收敛速度。
1 | func (m *Memberlist) pushPullTrigger(stop <-chan struct{}) { |
上面随机选取一个节点
1 | // pushPullNode does a complete state exchange with a specific node. |
1 | // sendAndReceiveState is used to initiate a push/pull over a stream with a |
gossip
节点通过udp协议向K个节点发送消息,节点从广播队列里面获取消息,广播队列里的消息发送失败超过一定次数后,消息就会被丢弃。发送次数参考Config 里的 RetransmitMul的注释。
1 | // gossip is invoked every GossipInterval period to broadcast our gossip |
因此将节点的状态分为3种
alive: 用于标识活跃节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216// aliveNode is invoked by the network layer when we get a message about a
// live node.
func (m *Memberlist) aliveNode(a *alive, notify chan struct{}, bootstrap bool) {
m.nodeLock.Lock()
defer m.nodeLock.Unlock()
state, ok := m.nodeMap[a.Node]
// It is possible that during a Leave(), there is already an aliveMsg
// in-queue to be processed but blocked by the locks above. If we let
// that aliveMsg process, it'll cause us to re-join the cluster. This
// ensures that we don't.
if m.hasLeft() && a.Node == m.config.Name {
return
}
if len(a.Vsn) >= 3 {
pMin := a.Vsn[0]
pMax := a.Vsn[1]
pCur := a.Vsn[2]
if pMin == 0 || pMax == 0 || pMin > pMax {
m.logger.Printf("[WARN] memberlist: Ignoring an alive message for '%s' (%v:%d) because protocol version(s) are wrong: %d <= %d <= %d should be >0", a.Node, net.IP(a.Addr), a.Port, pMin, pCur, pMax)
return
}
}
// Invoke the Alive delegate if any. This can be used to filter out
// alive messages based on custom logic. For example, using a cluster name.
// Using a merge delegate is not enough, as it is possible for passive
// cluster merging to still occur.
if m.config.Alive != nil {
if len(a.Vsn) < 6 {
m.logger.Printf("[WARN] memberlist: ignoring alive message for '%s' (%v:%d) because Vsn is not present",
a.Node, net.IP(a.Addr), a.Port)
return
}
node := &Node{
Name: a.Node,
Addr: a.Addr,
Port: a.Port,
Meta: a.Meta,
PMin: a.Vsn[0],
PMax: a.Vsn[1],
PCur: a.Vsn[2],
DMin: a.Vsn[3],
DMax: a.Vsn[4],
DCur: a.Vsn[5],
}
if err := m.config.Alive.NotifyAlive(node); err != nil {
m.logger.Printf("[WARN] memberlist: ignoring alive message for '%s': %s",
a.Node, err)
return
}
}
// Check if we've never seen this node before, and if not, then
// store this node in our node map.
var updatesNode bool
if !ok {
errCon := m.config.IPAllowed(a.Addr)
if errCon != nil {
m.logger.Printf("[WARN] memberlist: Rejected node %s (%v): %s", a.Node, net.IP(a.Addr), errCon)
return
}
state = &nodeState{
Node: Node{
Name: a.Node,
Addr: a.Addr,
Port: a.Port,
Meta: a.Meta,
},
State: StateDead,
}
if len(a.Vsn) > 5 {
state.PMin = a.Vsn[0]
state.PMax = a.Vsn[1]
state.PCur = a.Vsn[2]
state.DMin = a.Vsn[3]
state.DMax = a.Vsn[4]
state.DCur = a.Vsn[5]
}
// Add to map
m.nodeMap[a.Node] = state
// Get a random offset. This is important to ensure
// the failure detection bound is low on average. If all
// nodes did an append, failure detection bound would be
// very high.
n := len(m.nodes)
offset := randomOffset(n)
// Add at the end and swap with the node at the offset
m.nodes = append(m.nodes, state)
m.nodes[offset], m.nodes[n] = m.nodes[n], m.nodes[offset]
// Update numNodes after we've added a new node
atomic.AddUint32(&m.numNodes, 1)
} else {
// Check if this address is different than the existing node unless the old node is dead.
if !bytes.Equal([]byte(state.Addr), a.Addr) || state.Port != a.Port {
errCon := m.config.IPAllowed(a.Addr)
if errCon != nil {
m.logger.Printf("[WARN] memberlist: Rejected IP update from %v to %v for node %s: %s", a.Node, state.Addr, net.IP(a.Addr), errCon)
return
}
// If DeadNodeReclaimTime is configured, check if enough time has elapsed since the node died.
canReclaim := (m.config.DeadNodeReclaimTime > 0 &&
time.Since(state.StateChange) > m.config.DeadNodeReclaimTime)
// Allow the address to be updated if a dead node is being replaced.
if state.State == StateLeft || (state.State == StateDead && canReclaim) {
m.logger.Printf("[INFO] memberlist: Updating address for left or failed node %s from %v:%d to %v:%d",
state.Name, state.Addr, state.Port, net.IP(a.Addr), a.Port)
updatesNode = true
} else {
m.logger.Printf("[ERR] memberlist: Conflicting address for %s. Mine: %v:%d Theirs: %v:%d Old state: %v",
state.Name, state.Addr, state.Port, net.IP(a.Addr), a.Port, state.State)
// Inform the conflict delegate if provided
if m.config.Conflict != nil {
other := Node{
Name: a.Node,
Addr: a.Addr,
Port: a.Port,
Meta: a.Meta,
}
m.config.Conflict.NotifyConflict(&state.Node, &other)
}
return
}
}
}
// Bail if the incarnation number is older, and this is not about us
isLocalNode := state.Name == m.config.Name
if a.Incarnation <= state.Incarnation && !isLocalNode && !updatesNode {
return
}
// Bail if strictly less and this is about us
if a.Incarnation < state.Incarnation && isLocalNode {
return
}
// Clear out any suspicion timer that may be in effect.
delete(m.nodeTimers, a.Node)
// Store the old state and meta data
oldState := state.State
oldMeta := state.Meta
// If this is us we need to refute, otherwise re-broadcast
if !bootstrap && isLocalNode {
// Compute the version vector
versions := []uint8{
state.PMin, state.PMax, state.PCur,
state.DMin, state.DMax, state.DCur,
}
// If the Incarnation is the same, we need special handling, since it
// possible for the following situation to happen:
// 1) Start with configuration C, join cluster
// 2) Hard fail / Kill / Shutdown
// 3) Restart with configuration C', join cluster
//
// In this case, other nodes and the local node see the same incarnation,
// but the values may not be the same. For this reason, we always
// need to do an equality check for this Incarnation. In most cases,
// we just ignore, but we may need to refute.
//
if a.Incarnation == state.Incarnation &&
bytes.Equal(a.Meta, state.Meta) &&
bytes.Equal(a.Vsn, versions) {
return
}
m.refute(state, a.Incarnation)
m.logger.Printf("[WARN] memberlist: Refuting an alive message for '%s' (%v:%d) meta:(%v VS %v), vsn:(%v VS %v)", a.Node, net.IP(a.Addr), a.Port, a.Meta, state.Meta, a.Vsn, versions)
} else {
m.encodeBroadcastNotify(a.Node, aliveMsg, a, notify)
// Update protocol versions if it arrived
if len(a.Vsn) > 0 {
state.PMin = a.Vsn[0]
state.PMax = a.Vsn[1]
state.PCur = a.Vsn[2]
state.DMin = a.Vsn[3]
state.DMax = a.Vsn[4]
state.DCur = a.Vsn[5]
}
// Update the state and incarnation number
state.Incarnation = a.Incarnation
state.Meta = a.Meta
state.Addr = a.Addr
state.Port = a.Port
if state.State != StateAlive {
state.State = StateAlive
state.StateChange = time.Now()
}
}
// Update metrics
metrics.IncrCounter([]string{"memberlist", "msg", "alive"}, 1)
// Notify the delegate of any relevant updates
if m.config.Events != nil {
if oldState == StateDead || oldState == StateLeft {
// if Dead/Left -> Alive, notify of join
m.config.Events.NotifyJoin(&state.Node)
} else if !bytes.Equal(oldMeta, state.Meta) {
// if Meta changed, trigger an update notification
m.config.Events.NotifyUpdate(&state.Node)
}
}
}suspect: 当探测一些节点失败时,或者suspect某个节点的信息时,会将本地对应的信息标记为suspect,然后启动一个 定时器,并发出一个suspect广播,此期间内如果收到其他节点发来的相同的suspect信息时,将本地suspect的 确认数+1,当定时器超时后,该节点信息仍然不是alive的,且确认数达到要求,会将该节点标记为dead。 当本节点收到别的节点发来的suspect消息时,会发送alive广播,从而清除其他节点上的suspect标记。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87// suspectNode is invoked by the network layer when we get a message
// about a suspect node
func (m *Memberlist) suspectNode(s *suspect) {
m.nodeLock.Lock()
defer m.nodeLock.Unlock()
state, ok := m.nodeMap[s.Node]
// If we've never heard about this node before, ignore it
if !ok {
return
}
// Ignore old incarnation numbers
if s.Incarnation < state.Incarnation {
return
}
// See if there's a suspicion timer we can confirm. If the info is new
// to us we will go ahead and re-gossip it. This allows for multiple
// independent confirmations to flow even when a node probes a node
// that's already suspect.
if timer, ok := m.nodeTimers[s.Node]; ok {
if timer.Confirm(s.From) {
m.encodeAndBroadcast(s.Node, suspectMsg, s)
}
return
}
// Ignore non-alive nodes
if state.State != StateAlive {
return
}
// If this is us we need to refute, otherwise re-broadcast
if state.Name == m.config.Name {
m.refute(state, s.Incarnation)
m.logger.Printf("[WARN] memberlist: Refuting a suspect message (from: %s)", s.From)
return // Do not mark ourself suspect
} else {
m.encodeAndBroadcast(s.Node, suspectMsg, s)
}
// Update metrics
metrics.IncrCounter([]string{"memberlist", "msg", "suspect"}, 1)
// Update the state
state.Incarnation = s.Incarnation
state.State = StateSuspect
changeTime := time.Now()
state.StateChange = changeTime
// Setup a suspicion timer. Given that we don't have any known phase
// relationship with our peers, we set up k such that we hit the nominal
// timeout two probe intervals short of what we expect given the suspicion
// multiplier.
k := m.config.SuspicionMult - 2
// If there aren't enough nodes to give the expected confirmations, just
// set k to 0 to say that we don't expect any. Note we subtract 2 from n
// here to take out ourselves and the node being probed.
n := m.estNumNodes()
if n-2 < k {
k = 0
}
// Compute the timeouts based on the size of the cluster.
min := suspicionTimeout(m.config.SuspicionMult, n, m.config.ProbeInterval)
max := time.Duration(m.config.SuspicionMaxTimeoutMult) * min
fn := func(numConfirmations int) {
m.nodeLock.Lock()
state, ok := m.nodeMap[s.Node]
timeout := ok && state.State == StateSuspect && state.StateChange == changeTime
m.nodeLock.Unlock()
if timeout {
if k > 0 && numConfirmations < k {
metrics.IncrCounter([]string{"memberlist", "degraded", "timeout"}, 1)
}
m.logger.Printf("[INFO] memberlist: Marking %s as failed, suspect timeout reached (%d peer confirmations)",
state.Name, numConfirmations)
d := dead{Incarnation: state.Incarnation, Node: state.Name, From: m.config.Name}
m.deadNode(&d)
}
}
m.nodeTimers[s.Node] = newSuspicion(s.From, k, min, max, fn)
}dead: 当本节点离开集群时或者本地探测的其他节点超时被标记死亡,会向集群发送本节点dead广播。收到dead广播 消息的节点会跟本地的记录比较,当本地记录也是dead时会忽略消息,当本地的记录不是dead时,会删除本地 的记录再将dead消息再次广播出去,形成再次传播。 如果从其他节点收到自身的dead广播消息时,说明本节点相对于其他节点网络分区,此时会发起一个alive广播 以修正其他节点上存储的本节点数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60// deadNode is invoked by the network layer when we get a message
// about a dead node
func (m *Memberlist) deadNode(d *dead) {
m.nodeLock.Lock()
defer m.nodeLock.Unlock()
state, ok := m.nodeMap[d.Node]
// If we've never heard about this node before, ignore it
if !ok {
return
}
// Ignore old incarnation numbers
if d.Incarnation < state.Incarnation {
return
}
// Clear out any suspicion timer that may be in effect.
delete(m.nodeTimers, d.Node)
// Ignore if node is already dead
if state.DeadOrLeft() {
return
}
// Check if this is us
if state.Name == m.config.Name {
// If we are not leaving we need to refute
if !m.hasLeft() {
m.refute(state, d.Incarnation)
m.logger.Printf("[WARN] memberlist: Refuting a dead message (from: %s)", d.From)
return // Do not mark ourself dead
}
// If we are leaving, we broadcast and wait
m.encodeBroadcastNotify(d.Node, deadMsg, d, m.leaveBroadcast)
} else {
m.encodeAndBroadcast(d.Node, deadMsg, d)
}
// Update metrics
metrics.IncrCounter([]string{"memberlist", "msg", "dead"}, 1)
// Update the state
state.Incarnation = d.Incarnation
// If the dead message was send by the node itself, mark it is left
// instead of dead.
if d.Node == d.From {
state.State = StateLeft
} else {
state.State = StateDead
}
state.StateChange = time.Now()
// Notify of death
if m.config.Events != nil {
m.config.Events.NotifyLeave(&state.Node)
}
}
broadcast模块
broadcast模块是广播模块,提供了三个函数,最主要的函数是 getBroadcasts,返回一个广播的最大size,主要是用于填充udp包。很简单代码如下:
1 | // getBroadcasts is used to return a slice of broadcasts to send up to |
总结
回忆一下总体流程:
项目在memberlist.go 函数Create启动,调用sate.go中函数schedule
Schedule函数开启probe协程、pushpull协程、gossip协程
probe协程:进行节点状态维护
push/pull协程:进行节点状态、用户数据同步
gossip协程:进行udp广播发送消息。
memberlist利用点对点随机探测机制实现成员的故障检测,因此将节点的状态分为3种:
- StateAlive:活动节点
- StateSuspect:可疑节点
- StateDead:死亡节点
probe协程通过点对点随机探测实现成员的故障检测,强化系统的高可用。整体流程如下:
- 随机探测:节点启动后,每隔一定时间间隔,会选取一个节点对其发送PING消息。
- 重试与间隔探测请求:PING消息失败后,会随机选取N(由config中IndirectChecks设置)个节点发起间接PING请求和再发起一个TCP PING消息。
- 间隔探测:收到间接PING请求的节点会根据请求中的地址发起一个PING消息,将PING的结果返回给间接请求的源节点。
- 探测超时标识可疑:如果探测超时之间内,本节点没有收到任何一个要探测节点的ACK消息,则标记要探测的节点状态为suspect。
- 可疑节点广播:启动一个定时器用于发出一个suspect广播,此期间内如果收到其他节点发来的相同的suspect信息时,将本地suspect的 确认数+1,当定时器超时后,该节点信息仍然不是alive的,且确认数达到要求,会将该节点标记为dead。
- 可疑消除:当本节点收到别的节点发来的suspect消息时,会发送alive广播,从而清除其他节点上的suspect标记。。
- 死亡通知:当本节点离开集群时或者本地探测的其他节点超时被标记死亡,会向集群发送本节点dead广播
- 死亡消除:如果从其他节点收到自身的dead广播消息时,说明本节点相对于其他节点网络分区,此时会发起一个alive广播以修正其他节点上存储的本节点数据。
Memberlist在整个生命周期内,总的有两种类型的消息:
- udp**协议消息:**传输PING消息、间接PING消息、ACK消息、NACK消息、Suspect消息、 Alive消息、Dead消息、消息广播;
- tcp协议消息:用户数据同步、节点状态同步、PUSH-PULL消息。
push/pull协程周期性的从已知的alive的集群节点中选1个节点进行push/pull交换信息。交换的信息包含2种:
- 集群信息:节点数据
- 用户自定义的信息:实现Delegate接口的struct。
push/pull协程可以加速集群内信息的收敛速度,整体流程为:
- 建立TCP链接:每隔一个时间间隔,随机选取一个节点,跟它建立tcp连接,
- 将本地的全部节点 状态、用户数据发送过去,
- 对端将其掌握的全部节点状态、用户数据发送回来,然后完成2份数据的合并。
Gossip协程通过udp协议向K个节点发送消息,节点从广播队列里面获取消息,广播队列里的消息发送失败超过一定次数后,消息就会被丢弃。
参考:

